This post is part of The Software Architecture Chronicles, a series of posts about Software Architecture. In them, I write about what I’ve learned about Software Architecture, how I think of it, and how I use that knowledge. The contents of this post might make more sense if you read the previous posts in this series.
After graduating from University I followed a career as a high school teacher until a few years ago I decided to drop it and become a full-time software developer.
From then on, I have always felt like I need to recover the “lost” time and learn as much as possible, as fast as possible. So I have become a bit of an addict in experimenting, reading and writing, with a special focus on software design and architecture. That’s why I write these posts, to help me learn.
In my last posts, I’ve been writing about many of the concepts and principles that I’ve learned and a bit about how I reason about them. But I see these as just pieces of big a puzzle.
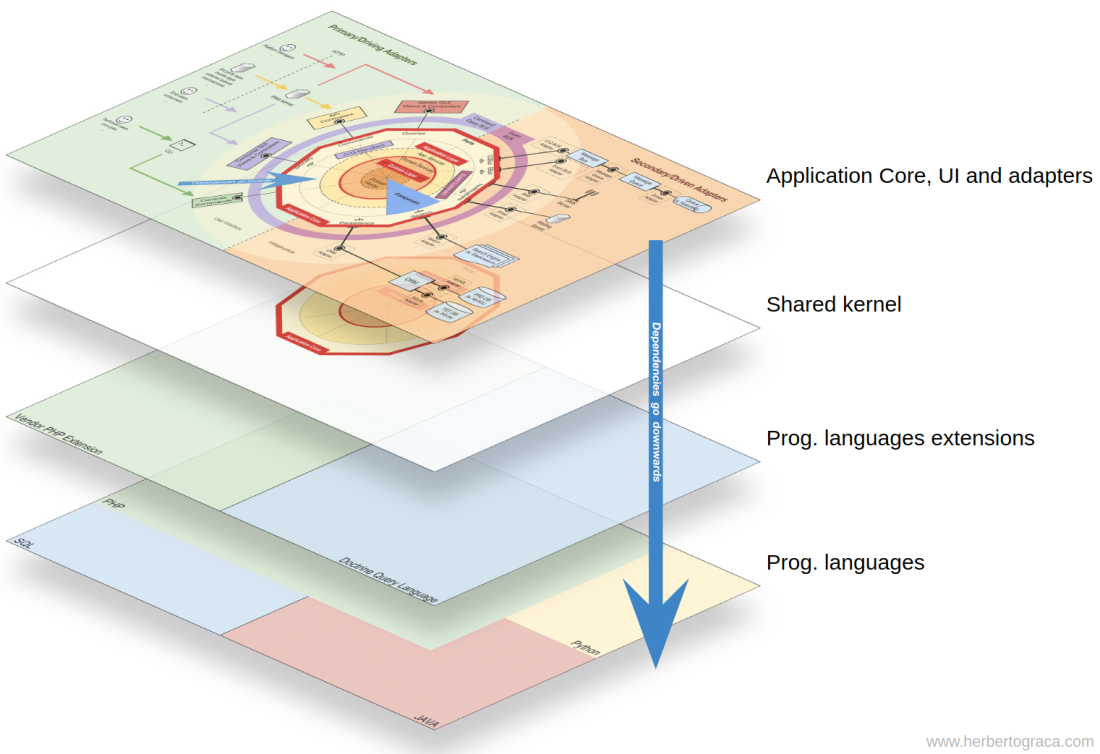
Today’s post is about how I fit all of these pieces together and, as it seems I should give it a name, I call it Explicit Architecture. Furthermore, these concepts have all “passed their battle trials” and are used in production code on highly demanding platforms. One is a SaaS e-com platform with thousands of web-shops worldwide, another one is a marketplace, live in 2 countries with a message bus that handles over 20 million messages per month.
- Fundamental blocks of the system
- Tools
- Connecting the tools and delivery mechanisms to the Application Core
- Application Core Organisation
- Components
- Flow of control
Fundamental blocks of the system
I start by recalling EBI and Ports & Adapters architectures. Both of them make an explicit separation of what code is internal to the application, what is external, and what is used for connecting internal and external code.
Furthermore, Ports & Adapters architecture explicitly identifies three fundamental blocks of code in a system:
- What makes it possible to run a user interface, whatever type of user interface it might be;
- The system business logic, or application core, which is used by the user interface to actually make things happen;
- Infrastructure code, that connects our application core to tools like a database, a search engine or 3rd party APIs.
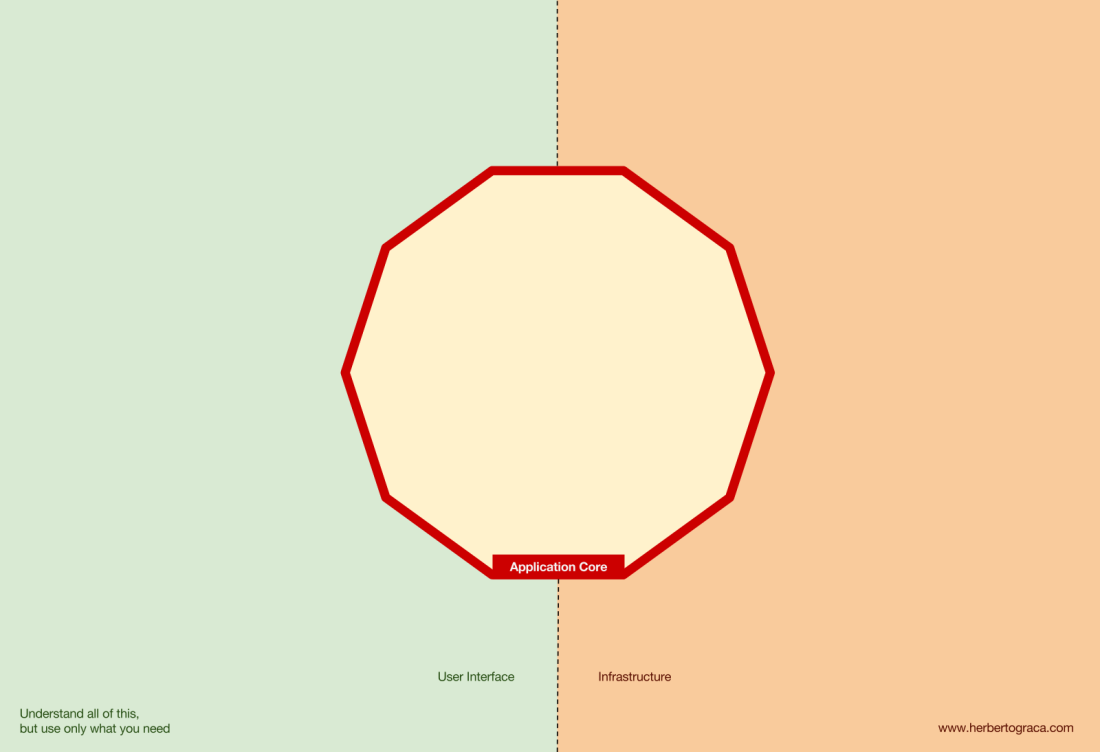
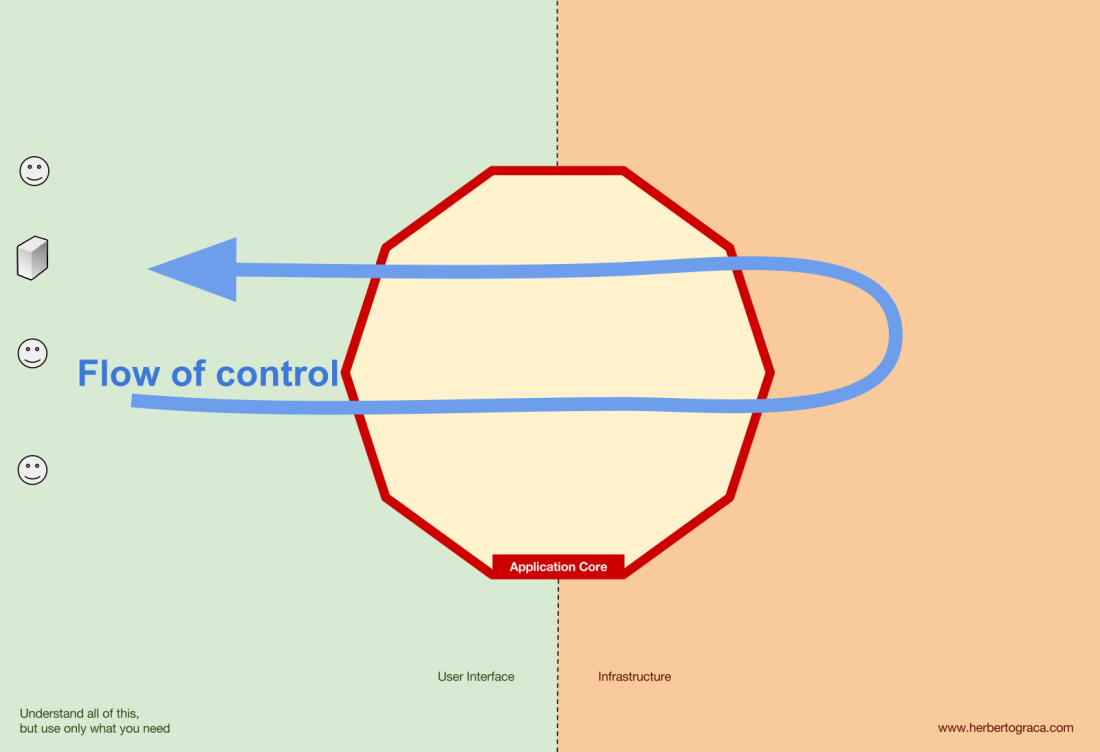
The application core is what we should really care about. It is the code that allows our code to do what it is supposed to do, it IS our application. It might use several user interfaces (progressive web app, mobile, CLI, API, …) but the code actually doing the work is the same and is located in the application core, it shouldn’t really matter what UI triggers it.
As you can imagine, the typical application flow goes from the code in the user interface, through the application core to the infrastructure code, back to the application core and finally deliver a response to the user interface.
Tools
Far away from the most important code in our system, the application core, we have the tools that our application uses, for example, a database engine, a search engine, a Web server or a CLI console (although the last two are also delivery mechanisms).
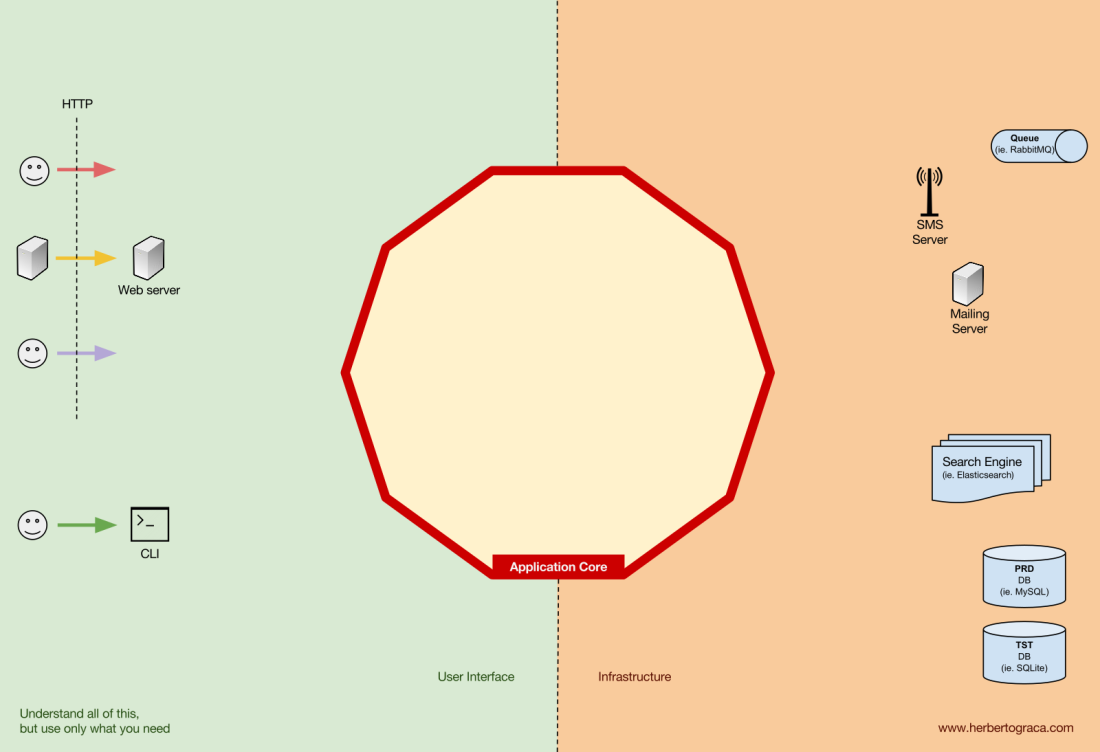
While it might feel weird to put a CLI console in the same “bucket” as a database engine, and although they have different types of purposes, they are in fact tools used by the application. The key difference is that, while the CLI console and the web server are used to tell our application to do something, the database engine is told by our application to do something. This is a very relevant distinction, as it has strong implications on how we build the code that connects those tools with the application core.
Connecting the tools and delivery mechanisms to the Application Core
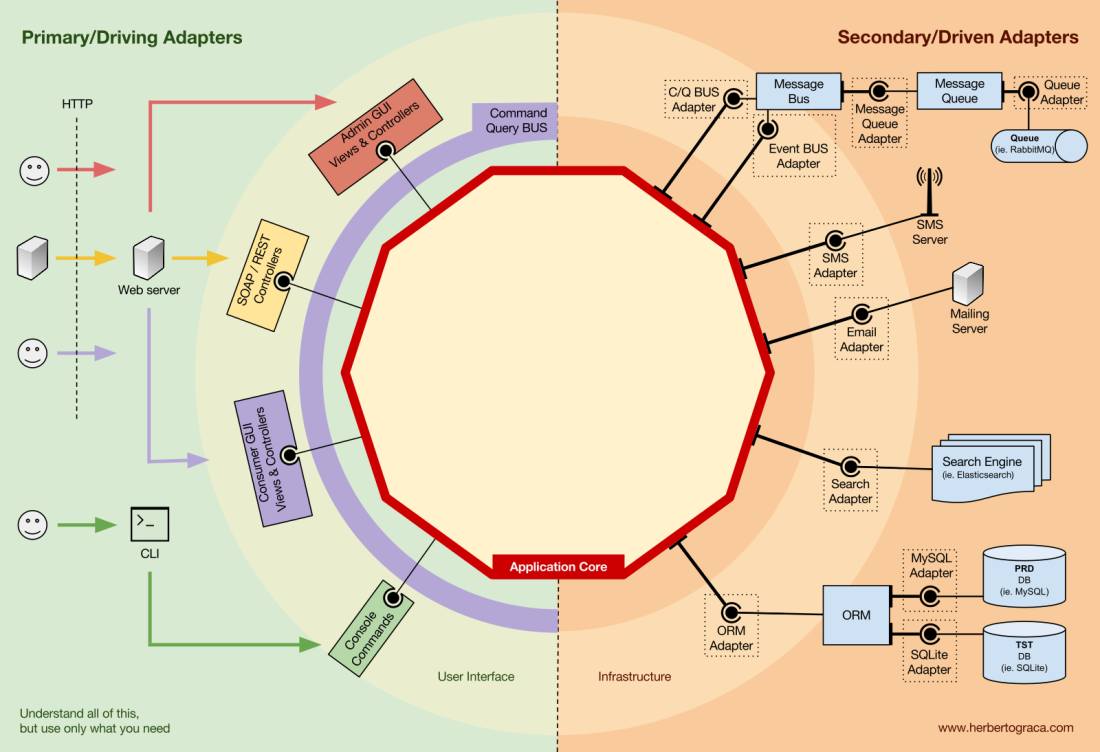
The code units that connect the tools to the application core are called adapters (Ports & Adapters Architecture). The adapters are the ones that effectively implement the code that will allow the business logic to communicate with a specific tool and vice-versa.
The adapters that tell our application to do something are called Primary or Driving Adapters while the ones that are told by our application to do something are called Secondary or Driven Adapters.
Ports
These Adapters, however, are not randomly created. They are created to fit a very specific entry point to the Application Core, a Port. A port is nothing more than a specification of how the tool can use the application core, or how it is used by the Application Core. In most languages and in its most simple form, this specification, the Port, will be an Interface, but it might actually be composed of several Interfaces and DTOs.
It’s important to note that the Ports (Interfaces) belong inside the business logic, while the adapters belong outside. For this pattern to work as it should, it is of utmost importance that the Ports are created to fit the Application Core needs and not simply mimic the tools APIs.
Primary or Driving Adapters
The Primary or Driver Adapters wrap around a Port and use it to tell the Application Core what to do. They translate whatever comes from a delivery mechanism into a method call in the Application Core.

In other words, our Driving Adapters are Controllers or Console Commands who are injected in their constructor with some object whose class implements the interface (Port) that the controller or console command requires.
In a more concrete example, a Port can be a Service interface or a Repository interface that a controller requires. The concrete implementation of the Service, Repository or Query is then injected and used in the Controller.
Alternatively, a Port can be a Command Bus or Query Bus interface. In this case, a concrete implementation of the Command or Query Bus is injected into the Controller, who then constructs a Command or Query and passes it to the relevant Bus.
Secondary or Driven Adapters
Unlike the Driver Adapters, who wrap around a port, the Driven Adapters implement a Port, an interface, and are then injected into the Application Core, wherever the port is required (type-hinted).
For example, let’s suppose that we have a naive application which needs to persist data. So we create a persistence interface that meets its needs, with a method to save an array of data and a method to delete a line in a table by its ID. From then on, wherever our application needs to save or delete data we will require in its constructor an object that implements the persistence interface that we defined.
Now we create an adapter specific to MySQL which will implement that interface. It will have the methods to save an array and delete a line in a table, and we will inject it wherever the persistence interface is required.
If at some point we decide to change the database vendor, let’s say to PostgreSQL or MongoDB, we just need to create a new adapter that implements the persistence interface and is specific to PostgreSQL, and inject the new adapter instead of the old one.
Inversion of control
A characteristic to note about this pattern is that the adapters depend on a specific tool and a specific port (by implementing an interface). But our business logic only depends on the port (interface), which is designed to fit the business logic needs, so it doesn’t depend on a specific adapter or tool.
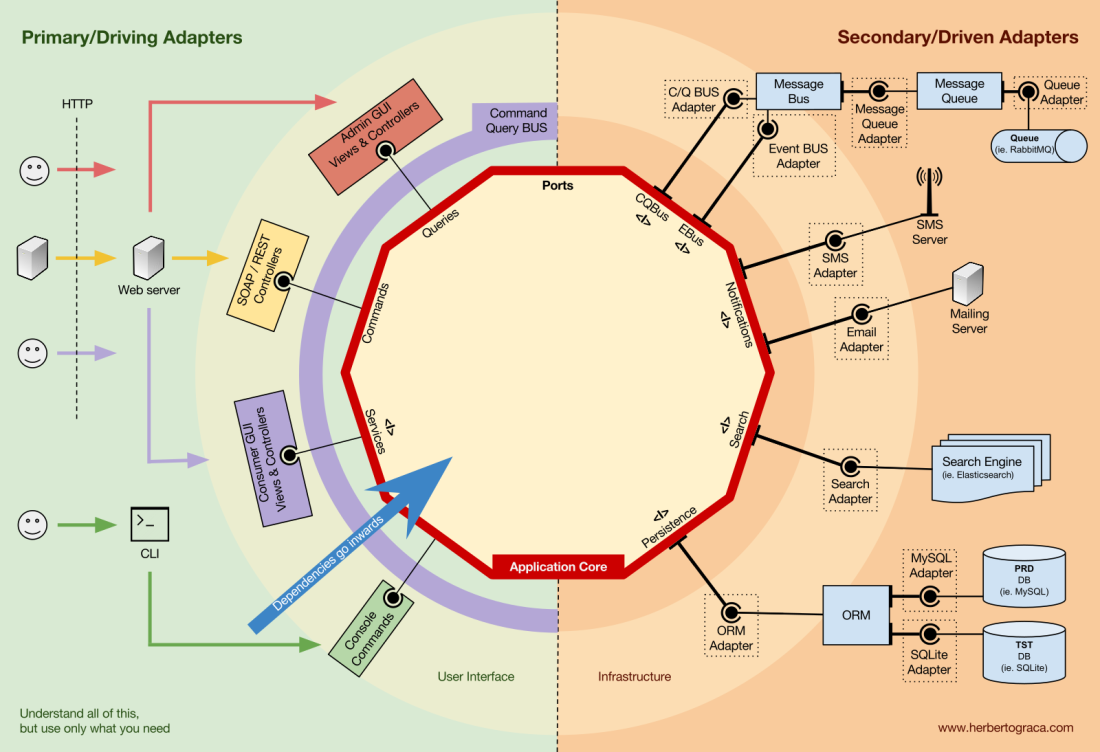
This means the direction of dependencies is towards the centre, it’s the inversion of control principle at the architectural level.
Although, again, it is of utmost importance that the Ports are created to fit the Application Core needs and not simply mimic the tools APIs.
Application Core organisation
The Onion Architecture picks up the DDD layers and incorporates them into the Ports & Adapters Architecture. Those layers are intended to bring some organisation to the business logic, the interior of the Ports & Adapters “hexagon”, and just like in Ports & Adapters, the dependencies direction is towards the centre.
Application Layer
The use cases are the processes that can be triggered in our Application Core by one or several User Interfaces in our application. For example, in a CMS we could have the actual application UI used by the common users, another independent UI for the CMS administrators, another CLI UI, and a web API. These UIs (applications) could trigger use cases that can be specific to one of them or reused by several of them.
The use cases are defined in the Application Layer, the first layer provided by DDD and used by the Onion Architecture.
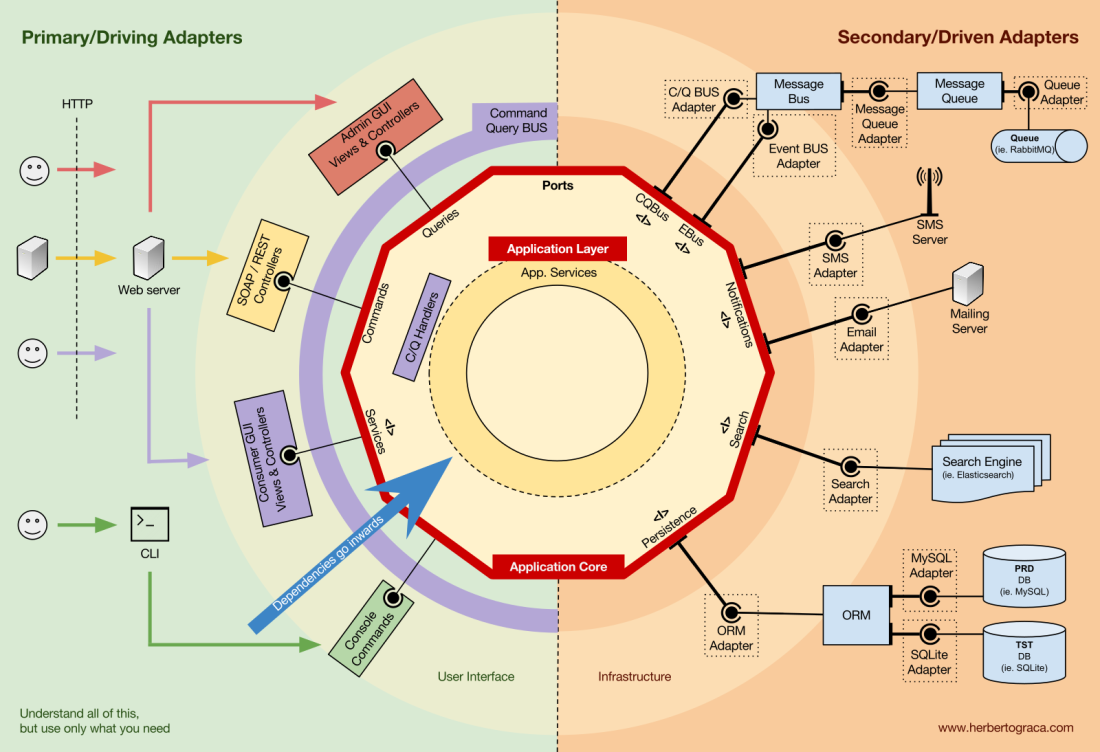
This layer contains Application Services (and their interfaces) as first class citizens, but it also contains the Ports & Adapters interfaces (ports) which include ORM interfaces, search engines interfaces, messaging interfaces and so on. In the case where we are using a Command Bus and/or a Query Bus, this layer is where the respective Handlers for the Commands and Queries belong.
The Application Services and/or Command Handlers contain the logic to unfold a use case, a business process. Typically, their role is to:
- use a repository to find one or several entities;
- tell those entities to do some domain logic;
- and use the repository to persist the entities again, effectively saving the data changes.
The Command Handlers can be used in two different ways:
- They can contain the actual logic to perform the use case;
- They can be used as mere wiring pieces in our architecture, receiving a Command and simply triggering logic that exists in an Application Service.
Which approach to use depends on the context, for example:
- Do we already have the Application Services in place and are now adding a Command Bus?
- Does the Command Bus allow specifying any class/method as a handler, or do they need to extend or implement existing classes or interfaces?
This layer also contains the triggering of Application Events, which represent some outcome of a use case. These events trigger logic that is a side effect of a use case, like sending emails, notifying a 3rd party API, sending a push notification, or even starting another use case that belongs to a different component of the application.
Domain Layer
Further inwards, we have the Domain Layer. The objects in this layer contain the data and the logic to manipulate that data, that is specific to the Domain itself and it’s independent of the business processes that trigger that logic, they are independent and completely unaware of the Application Layer.
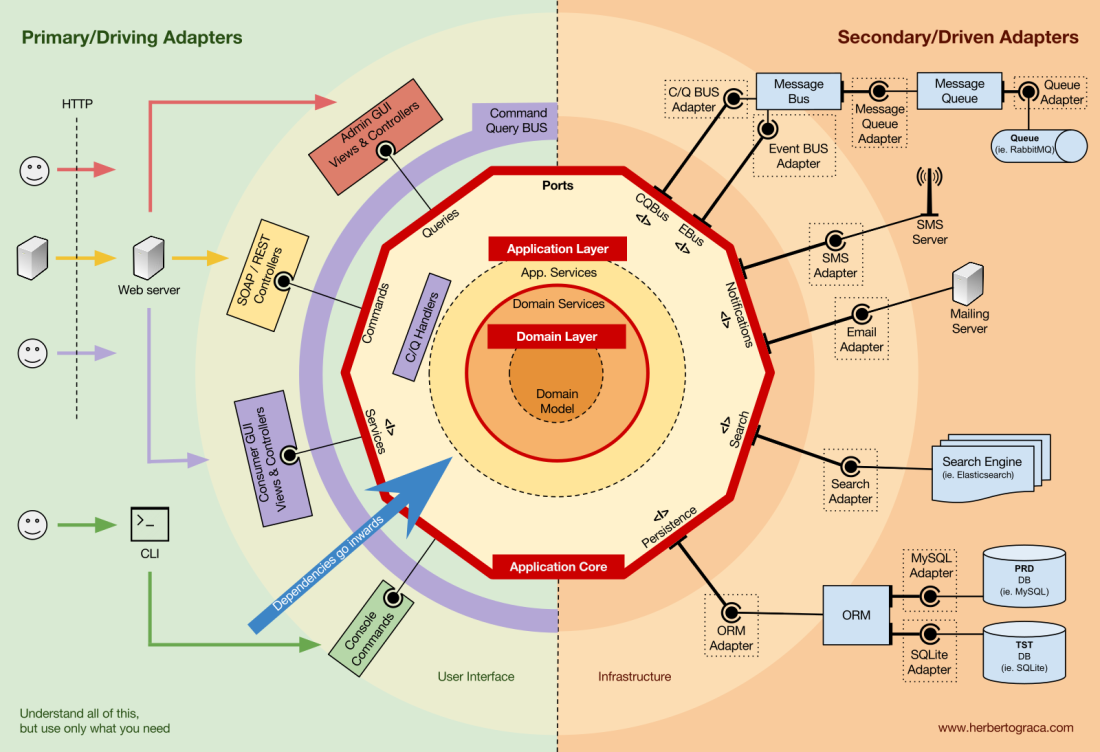
Domain Services
As I mentioned above, the role of an Application Service is to:
- use a repository to find one or several entities;
- tell those entities to do some domain logic;
- and use the repository to persist the entities again, effectively saving the data changes.
However, sometimes we encounter some domain logic that involves different entities, of the same type or not, and we feel that that domain logic does not belong in the entities themselves, we feel that that logic is not their direct responsibility.
So our first reaction might be to place that logic outside the entities, in an Application Service. However, this means that that domain logic will not be reusable in other use cases: domain logic should stay out of the application layer!
The solution is to create a Domain Service, which has the role of receiving a set of entities and performing some business logic on them. A Domain Service belongs to the Domain Layer, and therefore it knows nothing about the classes in the Application Layer, like the Application Services or the Repositories. In the other hand, it can use other Domain Services and, of course, the Domain Model objects.
Domain Model
In the very centre, depending on nothing outside it, is the Domain Model, which contains the business objects that represent something in the domain. Examples of these objects are, first of all, Entities but also Value Objects, Enums and any objects used in the Domain Model.
The Domain Model is also where Domain Events “live”. These events are triggered when a specific set of data changes and they carry those changes with them. In other words, when an entity changes, a Domain Event is triggered and it carries the changed properties new values. These events are perfect, for example, to be used in Event Sourcing.
Components
So far we have been segregating the code based on layers, but that is the fine-grained code segregation. The coarse-grained segregation of code is at least as important and it’s about segregating the code according to sub-domains and bounded contexts, following Robert C. Martin ideas expressed in screaming architecture. This is often referred to as “Package by feature” or “Package by component” as opposed to”Package by layer“, and it’s quite well explained by Simon Brown in his blog post “Package by component and architecturally-aligned testing“:



I am an advocate for the “Package by component” approach and, picking up on Simon Brown diagram about Package by component, I would shamelessly change it to the following:
These sections of code are cross-cutting to the layers previously described, they are the components of our application. Examples of components can be Authentication, Authorization, Billing, User, Review or Account, but they are always related to the domain. Bounded contexts like Authorization and/or Authentication should be seen as external tools for which we create an adapter and hide behind some kind of port.
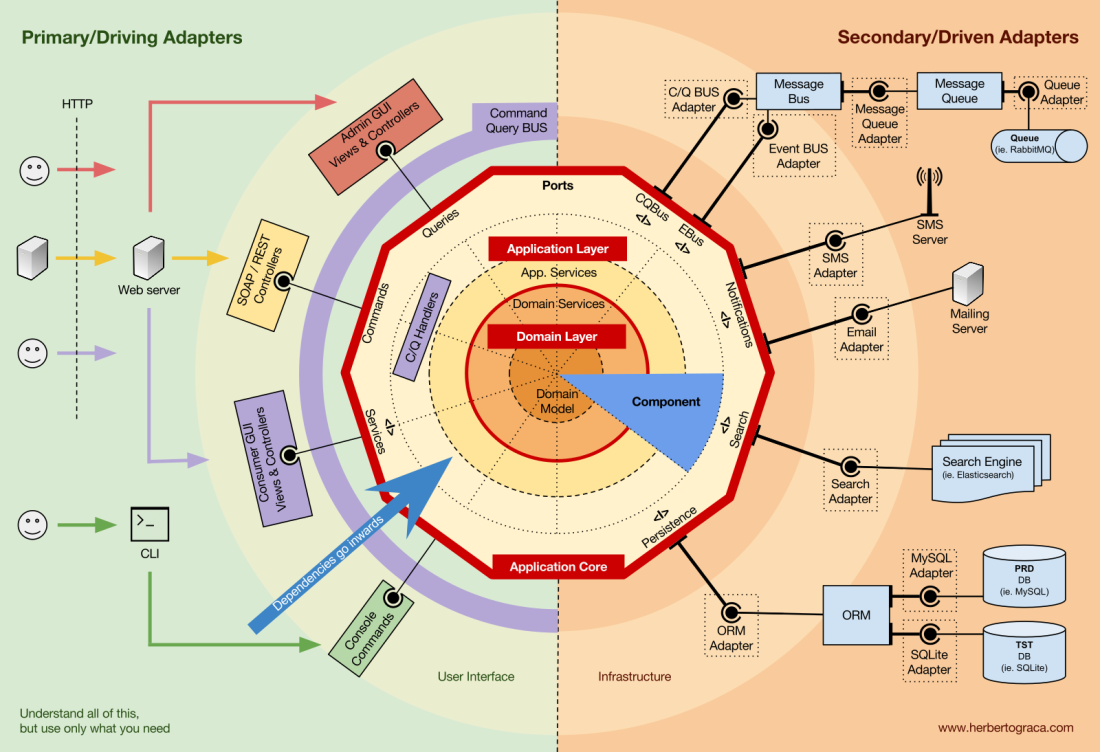
Decoupling the components
Just like the fine-grained code units (classes, interfaces, traits, mixins, …), also the coarsely grained code-units (components) benefit from low coupling and high cohesion.
To decouple classes we make use of Dependency Injection, by injecting dependencies into a class as opposed to instantiating them inside the class, and Dependency Inversion, by making the class depend on abstractions (interfaces and/or abstract classes) instead of concrete classes. This means that the depending class has no knowledge about the concrete class that it is going to use, it has no reference to the fully qualified class name of the classes that it depends on.
In the same way, having completely decoupled components means that a component has no direct knowledge of any another component. In other words, it has no reference to any fine-grained code unit from another component, not even interfaces! This means that Dependency Injection and Dependency Inversion are not enough to decouple components, we will need some sort of architectural constructs. We might need events, a shared kernel, eventual consistency, and even a discovery service!
Triggering logic in other components
When one of our components (component B) needs to do something whenever something else happens in another component (component A), we can not simply make a direct call from component A to a class/method in component B because A would then be coupled to B.
However we can make A use an event dispatcher to dispatch an application event that will be delivered to any component listening to it, including B, and the event listener in B will trigger the desired action. This means that component A will depend on an event dispatcher, but it will be decoupled from B.
Nevertheless, if the event itself “lives” in A this means that B knows about the existence of A, it is coupled to A. To remove this dependency, we can create a library with a set of application core functionality that will be shared among all components, the Shared Kernel. This means that the components will both depend on the Shared Kernel but they will be decoupled from each other. The Shared Kernel will contain functionality like application and domain events, but it can also contain Specification objects, and whatever makes sense to share, keeping in mind that it should be as minimal as possible because any changes to the Shared Kernel will affect all components of the application. Furthermore, if we have a polyglot system, let’s say a micro-services ecosystem where they are written in different languages, the Shared Kernel needs to be language agnostic so that it can be understood by all components, whatever the language they have been written in. For example, instead of the Shared Kernel containing an Event class, it will contain the event description (ie. name, properties, maybe even methods although these would be more useful in a Specification object) in an agnostic language like JSON, so that all components/micro-services can interpret it and maybe even auto-generate their own concrete implementations. Read more about this in my followup post: More than concentric layers.
This approach works both in monolithic applications and distributed applications like micro-services ecosystems. However, when the events can only be delivered asynchronously, for contexts where triggering logic in other components needs to be done immediately this approach will not suffice! Component A will need to make a direct HTTP call to component B. In this case, to have the components decoupled, we will need a discovery service to which A will ask where it should send the request to trigger the desired action, or alternatively make the request to the discovery service who can proxy it to the relevant service and eventually return a response back to the requester. This approach will couple the components to the discovery service but will keep them decoupled from each other.
Getting data from other components
The way I see it, a component is not allowed to change data that it does not “own”, but it is fine for it to query and use any data.
Data storage shared between components
When a component needs to use data that belongs to another component, let’s say a billing component needs to use the client name which belongs to the accounts component, the billing component will contain a query object that will query the data storage for that data. This simply means that the billing component can know about any dataset, but it must use the data that it does not “own” as read-only, by the means of queries.
Data storage segregated per component
In this case, the same pattern applies, but we have more complexity at the data storage level. Having components with their own data storage means each data storage contains:
- A set of data that it owns and is the only one allowed to change, making it the single source of truth;
- A set of data that is a copy of other components data, which it can not change on its own, but is needed for the component functionality, and it needs to be updated whenever it changes in the owner component.
Each component will create a local copy of the data it needs from other components, to be used when needed. When the data changes in the component that owns it, that owner component will trigger a domain event carrying the data changes. The components holding a copy of that data will be listening to that domain event and will update their local copy accordingly.
Flow of control
As I said above, the flow of control goes, of course, from the user into the Application Core, over to the infrastructure tools, back to the Application Core and finally back to the user. But how exactly do classes fit together? Which ones depend on which ones? How do we compose them?
Following Uncle Bob, in his article about Clean Architecture, I will try to explain the flow of control with UMLish diagrams…
Without a Command/Query Bus
In the case we do not use a command bus, the Controllers will depend either on an Application Service or on a Query object.
[EDIT – 2017-11-18] I completely missed the DTO I use to return data from the query, so I added it now. Tkx to MorphineAdministered who pointed it out for me.
In the diagram above we use an interface for the Application Service, although we might argue that it is not really needed since the Application Service is part of our application code and we will not want to swap it for another implementation, although we might refactor it entirely.
The Query object will contain an optimized query that will simply return some raw data to be shown to the user. That data will be returned in a DTO which will be injected into a ViewModel. ThisViewModel may have some view logic in it, and it will be used to populate a View.
The Application Service, on the other hand, will contain the use case logic, the logic we will trigger when we want to do something in the system, as opposed to simply view some data. The Application Services depend on Repositories which will return the Entity(ies) that contain the logic which needs to be triggered. It might also depend on a Domain Service to coordinate a domain process in several entities, but that is hardly ever the case.
After unfolding the use case, the Application Service might want to notify the whole system that that use case has happened, in which case it will also depend on an event dispatcher to trigger the event.
It is interesting to note that we place interfaces both on the persistence engine and on the repositories. Although it might seem redundant, they serve different purposes:
- The persistence interface is an abstraction layer over the ORM so we can swap the ORM being used with no changes to the Application Core.
- The repository interface is an abstraction on the persistence engine itself. Let’s say we want to switch from MySQL to MongoDB. The persistence interface can be the same, and, if we want to continue using the same ORM, even the persistence adapter will stay the same. However, the query language is completely different, so we can create new repositories which use the same persistence mechanism, implement the same repository interfaces but builds the queries using the MongoDB query language instead of SQL.
With a Command/Query Bus
In the case that our application uses a Command/Query Bus, the diagram stays pretty much the same, with the exception that the controller now depends on the Bus and on a command or a Query. It will instantiate the Command or the Query, and pass it along to the Bus who will find the appropriate handler to receive and handle the command.
In the diagram below, the Command Handler then uses an Application Service. However, that is not always needed, in fact in most of the cases the handler will contain all the logic of the use case. We only need to extract logic from the handler into a separated Application Service if we need to reuse that same logic in another handler.
[EDIT – 2017-11-18] I completely missed the DTO I use to return data from the query, so I added it now. Tkx to MorphineAdministered who pointed it out for me.
You might have noticed that there is no dependency between the Bus and the Command, the Query nor the Handlers. This is because they should, in fact, be unaware of each other in order to provide for good decoupling. The way the Bus will know what Handler should handle what Command, or Query, should be set up with mere configuration.
As you can see, in both cases all the arrows, the dependencies, that cross the border of the application core, they point inwards. As explained before, this a fundamental rule of Ports & Adapters Architecture, Onion Architecture and Clean Architecture.
Conclusion
The goal, as always, is to have a codebase that is loosely coupled and high cohesive, so that changes are easy, fast and safe to make.
Plans are worthless, but planning is everything.
Eisenhower
This infographic is a concept map. Knowing and understanding all of these concepts will help us plan for a healthy architecture, a healthy application.
Nevertheless:
The map is not the territory.
Alfred Korzybski
Meaning that these are just guidelines! The application is the territory, the reality, the concrete use case where we need to apply our knowledge, and that is what will define what the actual architecture will look like!
We need to understand all these patterns, but we also always need to think and understand exactly what our application needs, how far should we go for the sake of decoupling and cohesiveness. This decision can depend on plenty of factors, starting with the project functional requirements, but can also include factors like the time-frame to build the application, the lifespan of the application, the experience of the development team, and so on.
This is it, this is how I make sense of it all. This is how I rationalize it in my head.
I expanded these ideas a bit more on a followup post: More than concentric layers.
However, how do we make all this explicit in the code base? That’s the subject of one of my next posts: how to reflect the architecture and domain, in the code.
Last but not least, thanks to my colleague Francesco Mastrogiacomo, for helping me make my infographic look nice. 🙂
Translations
- Chinese, by Qinyusuain
- Japanese, by Tagoto
- Vietnamese, by Edward Hien Hoang
- Russian, by m1rko

Hi,
Could we put command handlers (adapter) to infrastructure layer, to prevent an extra abstraction for persistence mechanism (like IRepository) in the application layer and handling some complex commands or queries that is hard to abstract all of them in repository?
Is it a valid approach?
LikeLike
Sorry for the late reply.
I don’t think it’s a good idea to not have repositories, cozz of breaking SRP.
Though commands in the infrastructure might be fine.
LikeLike
thank you,
my question that why we should consider rest API /graphQL as user interfaces, they are extending our db ?
LikeLike
Because they do the same as an HTML UI, they are the layer that interacts with the user, be it human or machine.
They are primary adapters, adapting a delivery mechanism (http) to the application use case.
LikeLike
This is an excellent post that I reference and cite frequently.
One thing I noticed is that some of the images are hosted from this domain, and others are hosted from docs.google.com. I’d like to share this post with colleagues, but I’m at a Microsoft 365 shop that firewalls Google Docs for security reasons. My coworkers only see about half the images, as the others are blocked.
I believe it’s not all that uncommon for MS 365 shops to firewall Google Docs, and vice versa. Is there any chance you’d consider re-hosting the images so all are served directly from this domain? I believe that would give this post broader reach.
LikeLike
Hi Ian, tkx for your comment.
I personally believe that viewing documents in either Google Docs or Ms365 is not a security problem, so I’m not gonna change where they are hosted.
Tkx for the suggestion anyway.
LikeLike
Thanks for the reply.
I realized the Wayback Machine has a mirror of the article with all the images hosted from there, so that’s a possible workaround if anyone else finds themselves in a similar situation:
https://web.archive.org/web/20210222052235/https://herbertograca.com/2017/11/16/explicit-architecture-01-ddd-hexagonal-onion-clean-cqrs-how-i-put-it-all-together/
LikeLike
Hey, I made a translate from your article! I hope you enjoy it, because this article opened my eyes to many things in Computer Science.https://www.gawiga.com/blog/arquitetura-explicita
LikeLike
Hey, I made a translate from your article! I hope you enjoy it, because this article opened my eyes to many things in Computer Science. 🙂
https://www.gawiga.com/blog/arquitetura-explicita
LikeLike
Hi, great article and very well explained. Good job! Thank you!
I am confused with Repositories in application layer too as the others. I read your answers in comments, I understand your point of view that you don’t want to break the “onion”. However I still think entities should not be exposed there. It should be protected in Domain layer in the center. Because I will not see data as an external source. For me it’s the key of the whole business. My idea would be to put data(database) in the middle of “Domain”, like a “Data access” layer. Data will be protected and surrounded by Domain. Thus repositories should be certainly inside Domain to have access to “data access layer”. What do you think?
LikeLike
I think that ECB, hexagonal, onion and clean architectures, they all point in the opposite direction of what you are suggesting.
LikeLike
Thank you for this great post!
I feel this highlight “Ports are created to fit the Application Core needs and not simply mimic the tools APIs.” is very useful to ensure the code remains easy to modify to fit different use cases.
I somtimes see people justifying their codebase is loosely coupled merely by stating that they use an interface versus a concrete class. However, the interface specification they create is actually just mimicking the adapters/tools API. What happens is that, when you want to switch adapter/tools, it is still “very hard and unintuitive” despite having the interface. Because the interface is just mimicking the API of the old adapter versus if the interface is created to fit the Application core.
I think it will extremely helpful if you have a GitHub repo demonstrating a real example of using the architectural patterns in this post.
Some examples out there:
https://github.com/katzien/go-structure-examples
https://github.com/dotnet-architecture/eShopOnContainers
LikeLike
Tkx.
I do have the repo: https://github.com/hgraca/explicit-architecture-php
LikeLike
Could you justify why the Event Listeners are inside the Application Core?
I could easily see them on the same level as Primary Adapters.
Just like a RESTful Controller is invoked by HTTP Requests, an EventListener Controller would be invoked by events.
I believe that the dependency flow would still be satisfied.
Is this valid?
LikeLike
In event storming sessions there is a policy stickie, which represents business policies like “when a user registers, take money from their bank account”.
These policies translate to event listeners: an event is triggered by the UserComponent and listened to by the InvoicingComponent.
What i mean is that, while the primary adapter has a purely technical concern/responsibility of translating from a delivery mechanism (http, cli, …) to a use case, the listener has a business concern. To me, this means the listener should be in the core.
What I find debatable, is the location of the piece of code that reads events from a queue and delivers them to their listeners: is it a primary or secondary adapter?!
I tend to see it as a secondary adapter because its activities are not triggered by direct user action, but its debatable.
LikeLike
“I tend to see it as a secondary adapter because its activities are not triggered by direct user action, but its debatable.”
I’m having difficulty envisioning it as a secondary adapter, since a secondary adapter should be “driven”, not “driving”, as discussed above.
For example:
Let’s say we have a Kafka Consumer, and an Event comes.
In this case the Kafka Consumer should execute (drive) some functionality, based on the Event. This is analogous to a REST Controller responding to an Event (HTTP Request).
On the other hand, I see a Kafka Producer as a secondary adapter, since it is “driven”.
Maybe I over complicate things but I’d love to get your feedback on this, as well.
LikeLike
Well, we could say that the consumer is a primary adapter, and the producer is a secondary adapter, but:
We would separate them, putting them in 2 different root folders (primary/presentation vs secondary/infrastructure), but I feel this is gonna break the package cohesion principles, as we would be separating two pieces of code that are very strongly related, to the point that I consider them part of the same module.
I don’t think a queue consumer is part of a “presentation” layer: It does not return something to the user, nor does it respond to a direct command of a user (human or not). What it does, is to act on one of the tools of the system, a persistence mechanism like a DB: a queue.
LikeLike
“I don’t think a queue consumer is part of a “presentation” layer: It does not return something to the user, nor does it respond to a direct command of a user (human or not).”
Okay, this makes sense.
One more thing: How would the data flow?
A Consumer (Secondary Adapter) calling “something” (Event Listener) in the Application Core?
Because all of the dependencies above in the direction “Infrastructure -> Application Core” are done using “implements”.
Does this mean that a Secondary (Infrastructure) Adapter can have a reference to something in the Application Core, and call it?
Thank you so much for your time 🙂
LikeLike
Yes, it can. I try to avoid it though.
In this case, the consumer gets a message from the queue, hydrates it, sees its an event (maybe cozz it implements an event interface that belongs in the port), gets the event dispatcher from the DIC using a configured service id, and dispatches the event. The dispatcher is configured to be initialized with a list of event listeners but the code only knows about the event listeners interface (which belongs in a port). This way the infrastructure knows about the port, but not beyond it.
LikeLike
This makes sense. Thank you.
LikeLike
Hi @hgraca,
Have You ever consider to return ViewModel straight from ApplicationCore?
LikeLike
I considered it, but a view model is, by definition, tied to a controller action and template, it belongs in the presentation layer.
I have thought, though, of creating a query bus that would receive a viewmodel and figure out how to fill it in.
This would promote query reusability, the downside would be that queries would not be tailored/optimized to the needs.
LikeLike
You have right but I have some doubts with queries which returns to many data that UI view needs. Queries should return exactly for each use case. Right?
LikeLike
I don’t understand.
If a UI screen needs a set of data and our query returns exactly that set of data, how can that be “too many data that the UI view needs”?
LikeLike
Hi, Thanks for your complete article.
According to Simon brown talk about modular monolith, in vertical slice architecture that each feature split separately with its on internal layering, for communicating between feature sets controllers exposes for communication between components. But in component bases architecture that is like to vertical slice architecture components just like expose a public interface to other components could communicate with this component interface. Also, there is a sample in Simon GitHub for this. But you’re using event instead of using interfaces in order to communicate between components. Which one of the rule of component based architecture? Using event or interfaces like something Simon did?
View at Medium.com
https://github.com/techtribesje/techtribesje/tree/master/techtribes-updater/src/je/techtribes/component/activityupdater
LikeLike
The answer is, of course, it depends.
You can use any of those approaches or even both at the same time, it depends on the context, it depends on the needs of the project.
There are tradeoffs.
Using events, through an event bus (message queue), you need to account for eventual consistency, but on the other hand, the components are decoupled (you can change or remove a receiver without impacting the sender) and its more scalable because the receiving instances are in control of their own workload, because they pull work from the event bus at their own rate.
Using direct calls between components, you are explicitly coupling the components (which means that changes to the receiver can impact the sender) and the user might experience slowness because of all the internal calls, but on the other hand, its pretty much RPC, there is barely any eventual consistency. To make those calls faster, you can use gRPC, which is reportedly 10x faster than normal REST/HTTP calls. You can read about “service mesh architecture” for more info about this approach.
LikeLike
Thanks for answer,
Could we use Vertical Slice architecture with using event dispatcher for communication between feature-sets here? What is the advantage of component base architecture here? I think in your approach that we use the event they act the same.
LikeLike
You can, basically, imagine the slices as microservices. For me, conceptually, its the same.
Of course, implementation wise it’s not the same at all.
LikeLike
I have 2 question again 🙂
1) You mean about different implementation is folder structure like this for vertical slicing? Is it correct my assumption for vertical slicing feature-sets in below tree or should I change it?
───Componet-Based-Architecture
├───Core
│ ├───Component
│ │ ├───Blog
│ │ │ ├───Application
│ │ │ └───Domain
│ │ └───User
│ │ ├───Application
│ │ └───Domain
│ ├───Port
│ └───SharedKernel
├───Infrastructure
└───Presentation
───Vertical-Slice-Architecture
├───Blog
│ ├───Core
│ │ ├───Application
│ │ └───Domain
│ ├───Infrastructure
│ └───Presentation
└───User
├───Core
│ ├───Application
│ └───Domain
├───Infrastructure
└───Presentation
I found this sample for that purposehttps://github.com/kgrzybek/modular-monolith-with-ddd/tree/master/src/Modules/Payments
2) In your sample code explicit-architecture-php, for all components you used a shared infrastructure (contains adapter, …) folder in root of src folder that will share across all components. In component-bases architecture each component could have infrastructure in its own internal layer architecture according to Simon’s talk. Could we move infrastructure for each component inner that component? Like Simon’s C4 Model and have a unique UI for all of our components.
├───Componet-Based-Architecture
│ ├───Components
│ │ ├───Blog
│ │ │ ├───Core
│ │ │ │ ├───Application
│ │ │ │ └───Domian
│ │ │ └───Infrastructure
│ │ ├───Shared Kernel
│ │ └───User
│ │ ├───Core
│ │ │ ├───Application
│ │ │ └───Domain
│ │ └───Infrastructure
│ └───Presentations (Containers)
│ └───WebApp
https://c4model.com
LikeLike
Again, it depends on the context, it depends on the problem at hand.
That being said, i prefer the component based architecture with a UI and infrastructure separated from the backend.
Because the UI usually has complex screens/pages and workflows that require it to know about several backend components. So if we put the UI in each component, that means we will be coupling 2 components explicitly on the UI layer. Like, if page A lives in slice A and triggers 2 use cases, one in slice A and another in slice B, that means slice A knows about slice B, therefore we have coupling. Furthermore, the component arch. Works in both the cases where we have the UI built by the backend, or the UI as a standalone VueJs app that connects to the core through a graphql api.
And if we put the infrastructure in every slice, then when we need the same adapter in 2 slices we will be duplicating it…
Hope this helps.
LikeLike
Hi,
Thanks for your explanation 🙂 What I realize from your explanation is that packaging by feature (Vertical Slice) is very similar to component architecture, with the exception that in component based architecture the application (the UI) is separate from the components. And other things are almost equal in both.
LikeLike
Hi Herberto,
Thanks much for the article I learned quite a lot from it 🙂
I am currently planning to develop an application using this architecture. One of the components I will have is an Input handler which receives JSON messages over the network and then converts them into command objects before putting them on a command bus to be ferried to the respective handlers. I will have separate script (entry point for the application) which will among other components rely on the input handler to process all user inputs. My question is, which layer should this component (Input handler) belong to, should I treat as an adapter with a corresponding port in the application layer or something external to my application (just like how you’d treat a framework)?
Thanks again.
LikeLike
I’m a bit confused with the role of that separate script, so I’m not sure about my reasoning here, but nevertheless:
If the input handler receives a payload from the network, extracts data, and passes it on to a command bus, it sounds to me that the input handler is a primary/driver adapter, in the presentation layer, just like an http controller, or a CLI command.
Does this make sense?
LikeLike
That is really helpful.
Sorry about the confusion regarding the separate script. There is a lot more stuff that I will run alongside the the input handler. Think of it the script as a place where I instantiate all the other components of the application that I need to use. What I will include in there is similar a game loop where you have a while loop and with in it you update your entities, do the rendering, as you listen for user inputs. I just didn’t want to delve into all those details to avoid making my post really long. What you have pointed out makes sense to me and I think I know what to do now. 🙂
Thanks a lot for the prompt response I really appreciate it.
LikeLike
Super! Glad I could help 🙂
LikeLike
Thanks for your awesome article!
LikeLike
hi Herberto,
How about if my application depends on a Component (e.g. a Symfony component) which has its own complex interface, and I’m going to use most of the functionality (methods) of it.
Our app should not depend on an implementation (an instance of Component), instead it should depend on an interface, but how we define this new interface (like a RepositoryInterface)?
Should I define a wrapper interface and implement an adapter around the component, or I should depend on the component-provided interface instead, or a standard interface if possible (like PHP PSR interfaces)?
Thank you very much
LikeLike
Ideally, I would create the port way before even thinking about the actual implementation (your Symfony component), and then create an adapter for whatever implementation.
Most of the times, the PSR interfaces are good enough.
Last option is to conform to the external component.
That being said, all these options are valid, this is a conscious and intentional decision you need to make by analysing the tradeoffs of each option, together with your team, and ponder them in the current context of your project.
LikeLike
Thanks for your reply, it really helps.
LikeLike
Hi ! Great content, thanks for sharing and putting to work my brain cells :).
Quick question though: where would you add the ports & adapters corresponding to calls to an external API in the case where each Component would be concerned by specific endpoints of that external API ?
Thanks!
LikeLike
Tkx
Same as everything else, port in src/Core/Port/WhateverTool, and adapter in src/Infrastructure/WhateverTool/Whatever Provider.
I find that considering what component uses what is counter productive, as it will make it more complicated for no benefit and, who knows, maybe in the future one of the components will use other of the tool functionality.
The ports model what the core needs, not what a single component needs.
In one of my followup posts I talk about how I organise the code to reflect all this.
Hope this helps.
LikeLike
Hello colleague, very good article, the truth is that it describes in a very detailed way the relationship between all the concepts contained in each of the architectures in question.
Months ago I implemented a template for NodeJs that I published in Github alluding to some of these issues but from a more practical point of view, so I would be flattered if you come by and leave me your comments.
Thanks in advance.
Link: https://github.com/harvic3/nodetskeleton
LikeLike
Hello Mr Garcia! Excellent post, helped me a lot to understand more about CQRS and how to build the layers.
May I have your permission to translate to Portuguese-BR?
LikeLike
The picture in chapter “With a Command/Query Bus”, I don’t think application service should connect to repository interface, it should be domain service’s responsibility to connect to the repository interface.
LikeLike
If you consider a repository interface as part of the domain layer, and you even have a domain service, sure.
I consider the repository interface as part of the application layer, and i always have application services (use cases) that use the repositories.
I don’t consider a repository interface as part of the domain layer because the domain doesn’t care about persistence, it cares about business rules, and the repositories are about persistence.
Collections on the other hand can be specific to the domain layer.
LikeLike
I still very insistent to put repository interface as part of the domain layer, as domain(s) is possible microservice(s), and each microservice should keep its data as private, and for application service, we should use it as an orchestrator to coordinate domain services.
LikeLike
A microservice has use cases, therefore it has an application layer, therefore the repository interface can be in the application layer.
Orchestration would happen in the UI, by calling use cases from different microservices.
But there are different ways of thinking about it, this is just my way.
LikeLiked by 2 people
I completely agree with the author (hgraca), I still do not understand how a domain can have a contract (interface) repository, in fact that conflicts with the concept of domain where we have concrete things that model data.
The implementation of the repository is linked to the adapter layer and its specification (interface or contract) must be defined within the application layer.
LikeLike
Nice Article, Did you ever managed to implement it in real life? Do you have a code repository with examples?
LikeLike
Yes, i have a small demo: https://github.com/hgraca/explicit-architecture-php
LikeLike
Hi, I’m jaeyeoul from south korea.
I’ve be managing developer communities and publish articles for Korean Developer on doublem.org
I read this article. it was impressive to me.
I hope to translate your article. (It is not commercial)
Is it okay?
LikeLike
Sure, go ahead. Let me know when u publish it and i will put a link on my blog. 🙂
I was in Seul last year, btw. Great city, great ppl, great food, so much culture, loved it! If i would think of another adventure living abroad, that would be in my thoughts for sure!
LikeLike
Thanks a lot for this article and for all the series ! Extremely helpful
LikeLike
Hi,
I would like to contact with you to ask you permission to translate this post into Spanish…if you don’t mind, obviously.
Warmest regards.
LikeLike
Sure, go ahead. Let me know when it’s done and I will put a link on my blog.
LikeLike
Hi, awesome article, congratulations!!!
LikeLike
Hi Herberto
I guess that your explanation of Repository with knowning specific storage machanism is not good (different repositories for MySQL and MongoDB because of different languages used in them).
I think that if we plan to use different Storages we must create different adapters but repository implementation must not be changed in this case.
It is more suitable according to Ports&Adapters Architecture and others, because Application Core does not need to know about concrete implementations of Infrastructure, but in your explanation Repositories know about it.
LikeLike
Well, neither good nor bad. It depends. It’s all about the tradeoffs.
SQL and Mongo QL are languages, and we can decide to depend on the languages, not on the tools, but on the languages. So, we dont depend on MySQL, but we depend on SQL. Which means we should be able to use the same SQL repository with MySQL or Postgres. Or a DQL repository with Doctrine2 which in turn uses MySQL, Postgres or Mongo. Or a DQL repository with another ORM that implements DQL, maybe Doctrine3 or something else…
My point is that I decide to see query languages as languages, at the same level as PHP, HTML, Javascript or CSS.
I explain this in more detail in my next post “Explicit Architecture #02: More than concentric layers” https://herbertograca.com/2018/07/07/more-than-concentric-layers/
The tradeoff of implementing it as you suggest is the complexity of implementing an adapter for SQL and another one for MongoQL that comply with the same persistence port.
What is important is to understand the tradeoffs so that we make a conscient & knowledgeable decision and that the team supports and understands the technical vision.
I hope this helped clarify my ideas.
LikeLike
I preffer to use one language as language of architecture core implementation and don’t like to mix different languages in one scope. So I think, for example, about C# as language of architecture core impementation (or one of its part if we talk about micro-services architecture, for example) and SQL/HQL/GraphQL as concrete infrastructure implementaion and prefer to move them to Adapters.
It’s my thoughts and you have your own.
Thank you, Herberto.
LikeLike
Hi Herberto.
Great article!
Could you fix the link to Russian translation? https://habr.com/ru/post/427739/
The current one leads to an e-commerce site.
LikeLike
Hi, tkx for letting me know.
Unfortunately, I don’t know of another Russian translation, so I had to remove the link.
If you know of one, let me know and I will add it.
LikeLike
Hi.
I posted the actual link with Russian translation in the comment above. Probably I wasn’t clear trying to say it. Sorry for the confusion. 🙂
The translation is here: https://habr.com/ru/post/427739/
LikeLike
Hi Herberto,
Here is the Russian translation:
https://habr.com/ru/post/427739/
LikeLike
Hi Herberto,
Apparently my previous comments didn’t pass moderation for some reason.
The Russian translation is under the habr link I sent you in the previous comment on March, 5, 2020
LikeLike
Hey, i got your comment but couldn’t do it at that moment and then forgot.
Sorry about that, and tkx. 🙂
LikeLike
Oh, great!
Btw, I didn’t make the translation, I only found it. The translator is someone nicknamed m1rko.
LikeLike
Tkx again. It’s corrected now.
LikeLike
Hi,
In our application we use MongoDB for persistence. We also use Solr to improve performance on some of the querying in the application (“LIKE” searches and “JOINS” are not super fast in MongoDB). We are now trying to figure out if we should have a ISearch interface to handle the queries where we use Solr OR if our persistence adapter should be used and the adapter uses both MongoDB AND Solr to solve “all” querying?
What would motivate the ISearch port from a domain perspective? In our case the reason for using Solr is that MongoDB has limitations (performance) on some of our queries. Any thoughts on this would be much appreciated!
LikeLike
Hi,
I think there is no domain reason to use a Search port, the reason is technical. Its about performance, while the domain is about business concepts, ideas, flows, user journey, etc.
All ports and adapters are technical concerns. Its a way of structuring our code to make it easier to adapt, change. For example, you might want to use a search engine because it fits a user journey (in which case is a domain reason) or u might wanna use it as a cache mechanism (in which case is a technical reason) but you can do both with or without ports and adapters.
The advantage of ports and adapters is really technical: it makes the code base easier to change, therefore adaptable to future requirements, scalable and future proof.
LikeLike
Thank u for taking the time to reason about the question, keep up the great work!
LikeLike
Hi, after reading your article I finally understand the design. It really is a awesome reference which puts everything together!
But as I am not that familiar with that topic, may you help me with my questions?
How is the event flow for domain events? Especially how do other domains receive and handle them?
Thank you for sharing!
LikeLike
Tkx 🙂
Well, if it’s within a monolith and in sync, in one domain there will be some code instantiating an event and passing it to a dispatcher. This dispatcher contains a list of listeners (objects) that are listening to different events so it just passes the given event to the listeners listening to that event type. The listeners live in a different component.
This way the receiving component has no knowledge about the component sending the event, although they both know about the event and the dispatcher.
If we have an async context, then the dispatcher, instead of delivering the event directly to the listener, will serialize and persist the event into a queue. In its most simple form you can think of this queue as a database table with the serialized events there, although its best to use something like rabbitqm or kafka. Then, there will be “workers”, which can be just simple CLI applications running in the cluster, getting those events out of the queue and doing something with them, whatever that is.
I hope this answers your question.
Good luck 🙂
LikeLike
Thank you for this post, very insightful. Concepts like these provide very useful guidelines when building software, especially when building greenfield. Brownfield however, the guidelines can also be challenging every now and then.
From that point of view I was wondering what you’re opinion is on building for brownfield landscapes, especially those where there are parts of the landscape one cannot change. One of my customers has a centralized application in which a lot of their domain lives; both data as well as logic. Over time this system has become the center of their landscape and they’ve built several other applications around it, which depedency wise is a bit messy. So in those kinds of scenarios, would you have any best practices that you can apply on how to deal with such a system in the scope of the entire landscape? This particular application comes from an external vendor so it’s really can’t be changed in any way. There is however some API’s and they even do some direct interactions on database level. So it’s quite possible to create ports / adapters which would interact with this system, but I’m not quite sure on how to position it then. Would you regard the entire system as one, or conceptually split it up across services which mimic the domain models better?
PS: I realise this is a difficult question to answer without too much context, sorry about that 🙂
LikeLike
Hi,
Well, it all depends on what you want to do with that centralized application.
If no changes are needed (or very few per year), then do nothing. If it ain’t broken, don’t fix it.
The other satellite applications that need to communicate with it, should have their own port&adapter, so that if in the future you need to change it, it will be easier to do.
If you need to improve the responsiveness of the overall system as well as the resilience, I suggest starting to use a command bus. Your satellite applications will send messages to that command bus instead of sending it to the central application and waiting for it in order to send a reply to the user., so responsiveness will be improved. Then you will have a worker pulling messages from the bus and sending them to the central application. If the messages fail, they go back to the queue, you can fix the problem and resend them to the central application. This will increase resilience.
If you wanna replace the central application with something else (a new monolith, or microservices), inits entirety or only parts of it, then I suggest using the strangler pattern. Maybe together with an event store, depending on your needs.
Hope this helps.
Good luck.
LikeLike
Hi, I liked your article very much and I’d like to translate it into Spanish if it is not already available, may I?
LikeLike
Sure, let me know when you do and I’ll add it at the bottom.
LikeLike
Hi again,
Just a conceptual doubt regarding Shared Kernel. I basically see it at the moment as a set of DTOs and Enums shared between the Client and the Application Core, and in some cases extended with Application Events or Specifications. In this last case, I would need to use Domain Entities to be able to define shared Specifications between services, but in this way I would need a reference to my Domain Layer in the Shared Kernel, what I find not very correct.
Which will be your opinion about to add Domain references in the Shared Kernel?
Thanks in advance.
LikeLike
If i understood correctly:
– a reference to the domain layer in the shared kernel doesn’t sound good, indeed;
– a Shared Kernel, in the vision i explain in my blog, should indeed contain the types of classes you mention, except for the Specifications;
– a specification belongs in the Domain layer of one component, and can only be used within that component or within primary or secondary adapters;
– the shared kernel, in the vision i explain in my blog, is used to contain classes without domain logic (although might belong to the domain layer, like an entity ID), used for communication between components, through the use of events.
This said, of course some times we hit edge cases and then we need to be creative, but i have not found them yet. (As far as i remember)
LikeLike
Thanks for sharing this information
LikeLike
Dear Herberto,
I noticed that you use the plug/socket pair icons to describe an interface (plug) and its implementation (socket). The primary adapters on the left side of your outer ring follow this intention but the secondary adapters on the right side do not.
Shouldn’t they not follow that same pattern? So the core defines them as interfaces (plugs) and the infrastructure implements them (sockets)?
Just wondering if I got it right or wrong.
Frank
LikeLike
Good question.
They both are adapters, but they adapt different types of artefacts and therefore the pattern is slightly different.
On the right side (secondary adapters) the port/adapter adapts a tool/library to the core needs:
– the core defines an interface, which is the port
– the adapter implements the interface
– the adapter wraps around an external tool/library
– the adapter receives/sends a set of data from/to the external tool/library
On the left side (primary adapters) the port/adapter adapts a delivery mechanism (HTTP/HTML, HTTP/JSON, CLI, …) to the core needs:
– the core implements the use cases (application services or command handlers), which are the ports
– the adapter wraps around the use case
– the adapter receives/sends a message/payload from/to the delivery mechanism
So what I wanted to express with the different notation is that they follow slightly different patterns and what we usually call an MVC controller, in Ports&Adapters is a primary adapter, because its responsibility is to simply extract data from a payload (ie. HTTP request) and pass it on to a use case implemented by the application core, and vice versa.
Hope this makes it more clear.
LikeLiked by 1 person
Ok, then I got it.
You use the graphical symbols as defined in the context of UML where a lollipop notation (which I called plug) is used for offering an interface and points to the side of the implementation and the socket notation is the user side and points to the side consuming an interface.
In this sense the lollipops point to the core for primary ports but point from the core for secondary ports, right?
There is another (maybe more technical?) interpretation that says the lollipop is the interface and the socket is the implementer. I got the wrong impression that you used this interpretation and therefore expected to have the right side the lollipops pointing to the domain.
Thanks for the explanation!
LikeLike
I understand.
Yeah, I didn’t follow any technical view, i tried to make visible what wraps around what.
So on the primary adapter side the adapter wraps around the use case provided by the core, but on the secondary adapter side the adapter wraps around the 3rd party tool/lib.
LikeLiked by 1 person
Really nice and well done explanation! Just a litle point by DDD reference. A Repository expresses the concept of aggregation for a domain model and it should be seen as a well-known domain service and by this it would belong to the domain layer.
LikeLike
Tkx for your compliments and thoughts.
I know that in Onion Architecture, Jeffrey Palermo also places repositories in the Domain layer. In DDD, however, i do not recall any reference about it.
Anyway, I disagree with it.
Reason being that a Repository depends on a data source, or actually its port which is part of the Application layer. So if we put the repositories in the Domain layer it will break the dependency direction rule of concentric layers architecture, which states that inner layers must not depend on outer layers.
I think the reason why we sometimes see them as part of the Domain layer is because some queries need domain knowledge. However, those queries are nothing more than filters, which are built in a programming language like SQL. I think it is fine for any of the concentric layers to depend on any programming language, so i create filter objects (in the lines of Specification objects) in the Domain layer which can then be used by Repositories, QueryObjects, or even Collections.
Collections, btw, are very similar to Repositories, but do belong in the Domain layer because they do not depend on any persistence mechanism.
I hope this helped you understand my view. 🙂
LikeLike
Well explained. But ports on application service defines the contract which actually uses domain model.. so repository layer must be exposed in repost layer
LikeLike
Im not sure i understood your “but” 🙂
There is no repository layer, there is an Application Layer, and repositories belong there. Repositories then use a persistence port, which is implemented by an adapter wrapping around an ORM (for example).
Repositories don’t know about the specific adapter they will get, but they might know and use a query language (ie SQL), because it’s a language, it’s at the same level as PHP, or JAVA, or ….
Hope this helps.
LikeLike
I’m wandering if there is another way to do it via ‘Inversion of Control’ ? How about defining the repository contract in the Domain layer, and we could implement the interfaces in other layer(e.g. infrastructure layer). After that we assemble them on the fly.
LikeLike
In that case, we don’t even need to put the repository interfaces in the domain layer, it’s enough to put them in the application layer and, as you say, the repository implementations in the infrastructure layer. Then the repositories themselves work as adapters. The downside then is that if we want to change the ORM, instead of changing the ORM adapter, we need to implement ALL repositories as they are all adapters.
LikeLike
Hello @cray,
Maybe my approach described in this comment could be useful for you:
https://herbertograca.com/2017/11/16/explicit-architecture-01-ddd-hexagonal-onion-clean-cqrs-how-i-put-it-all-together/comment-page-1/#comment-2404
LikeLike
Thankyou… useful information…Thank you for this awesome information.
LikeLike
Thanks for sharing this information
LikeLike
Thanks for the great article. I still have some queries when comparing this kind of clean/onion/hexagonal architecture to n-tier architecture which has APIs and code implemented by interfaces (can say DI). Are they just similar patterns just distinguished by different fancy names?
LikeLike
I would say they complement each other.
LikeLike
Hope is well for you sir, thank you for this article,
would you mind sharing the code with this kind of implmented architecture? thanks
LikeLike
Sure:
https://github.com/hgraca/explicit-architecture-php
LikeLike
Great articles. I have one question. Does the implementation of the port for driving adapter belong to the application core?
LikeLike
Tkx.
Yes it does, the controller is the adapter, which triggers a use case (the port).
LikeLike
Hi, awesome article, what I am wondering about for some time is if application layer should be completely free from any external libraries dependencies, such as ready service bus (like MediatR in .NET case), mappers etc. so it should contain only plain c# or java classes and interfaces, or it is ok to add some external service bus or sth. to that layer.
My approach would be that application layer should contain playn language classes and interfaces but i am not sure if my approach is not too puristic 🙂
LikeLike
The application layer should contain the use cases and depend only on abstractions. However, this is the theory. In practice, you should do what your project requires you to do.
Check my answer here: https://herbertograca.com/2017/11/16/explicit-architecture-01-ddd-hexagonal-onion-clean-cqrs-how-i-put-it-all-together/comment-page-2/#comment-18281
LikeLike
Hi Herberto
Thanks for this post, it’s a reference I return to often!
My team and I are looking to refactor from a relatively messy/unstructured monolith to a modular one using these patterns. I was wondering whether you think it is worth the overhead incurred in fully decoupling components vs having components depend on the interfaces exposed by other components? It seems to me that for a small team building a monolith with no plans to transition to microservices it may not be worth it. For larger organisations where sub teams map to components or those aiming for microservices that decoupling becomes more valuable. I may be missing something here though.
Thanks again
Ben
LikeLike
Cool, I’m glad, and flattered, that u find it useful ☺
Regarding your question, I don’t believe in a “silver bullet”. I think it always depends on the project requirements and the team building it. It’s always about trade-offs, so ask your team where are the trade-offs positive if implementing a port/adapter.
For example, in my current project we have a port/adapter for our SMS provider because it is easy to do, and the SMS providers compete and change prices often so we want it to be easy to change SMS providers, furthermore we might want different providers per country, so having port/adapters here gives us tremendous flexibility and the trade-offs are extremely positive. However, we do not have a port/adapter for the ORM because it is VERY unlikely that we will ever change it and the complexity of doing it is VERY high, so the trade-offs are negative.
So, put your team to think about where it makes sense to do it, and don’t do it just because of “purism”, or a se arch for perfection. And if at so e point u see its advantageous to have the port/adapter, u can always add it then.
Good luck. 🙂
LikeLike
Hi, thanks for getting back to me.
The coupling I was referring to is that between the higher level components of the application. Those that correspond to the sub domains / bounded contexts. Allowing Billing to call the interfaces exposed by the User component directly to use your examples.
Having said that I’m guessing your answer would probably be the same 😊
In our particular case with a small team and a single data source I suspect it makes sense to move towards a modular but deliberately coupled architecture which can then be completely decoupled later if necessary through the use of events, shared kernels, etc.
If you’ve got time, I was wondering whether anything has changed dramatically in your approach since you wrote this?
Anyway, I’ll definitely be referring to this post as we work through the process, it’s much appreciated.
LikeLike
Hi Herberto,
I’m quite surprised you said that in the specific project you’ve mentioned you’re not using a port/adapter for an ORM.
I completely understand that in most cases creating a wrapper around an ORM just limits its functionality and creates more problems, but if you are not using any port/adapter for ORM then isn’t it kind of negation of hexagonal architecture principles?
Your “Application Core” then either have to depend directly on the ORM library (but as you described Application Core should be library/framework agnostic) or reference Infrastructure layer where you have ORM configured but then we’re breaking a dependency rule (point inward and not outward).
Comment would me appreciated as I try to understand hexagonal arch better 🙂
LikeLike
It’s good that you try to understand hexagonal architecture, but keep in mind that the biggest challenge/problem is not a technical one: its people!
When working in a team, we can’t always make the choices we would like to. As they say in the army, “no plan survives contact with the enemy”. 😀
Regarding broken rules, on that project indeed the dependency direction rule was one of the rules broken by not having a port for the ORM. However, the Domain layer was still isolated, only the application layer was leaked onto by the ORM.
LikeLike