This post is part of The Software Architecture Chronicles, a series of posts about Software Architecture. In them, I write about what I’ve learned on Software Architecture, how I think of it, and how I use that knowledge. The contents of this post might make more sense if you read the previous posts in this series.
When creating an application, the easy part is to build something that works. To build something that has performance despite handling a massive load of data, that is a bit more difficult. But the greatest challenge is to build an application that is actually maintainable for many years (10, 20, 100 years).
Most companies where I worked have a history of rebuilding their applications every 3 to 5 years, some even 2 years. This has extremely high costs, it has a major impact on how successful the application is, and therefore how successful the company is, besides being extremely frustrating for developers to work with a messy code base, and making them want to leave the company. A serious company, with a long-term vision, cannot afford any of it, not the financial loss, not the time loss, not the reputation loss, not the client loss, not the talent loss.
Reflecting the architecture and domain in the codebase is fundamental to the maintainability of an application, and therefore crucial in preventing all those nasty problems.
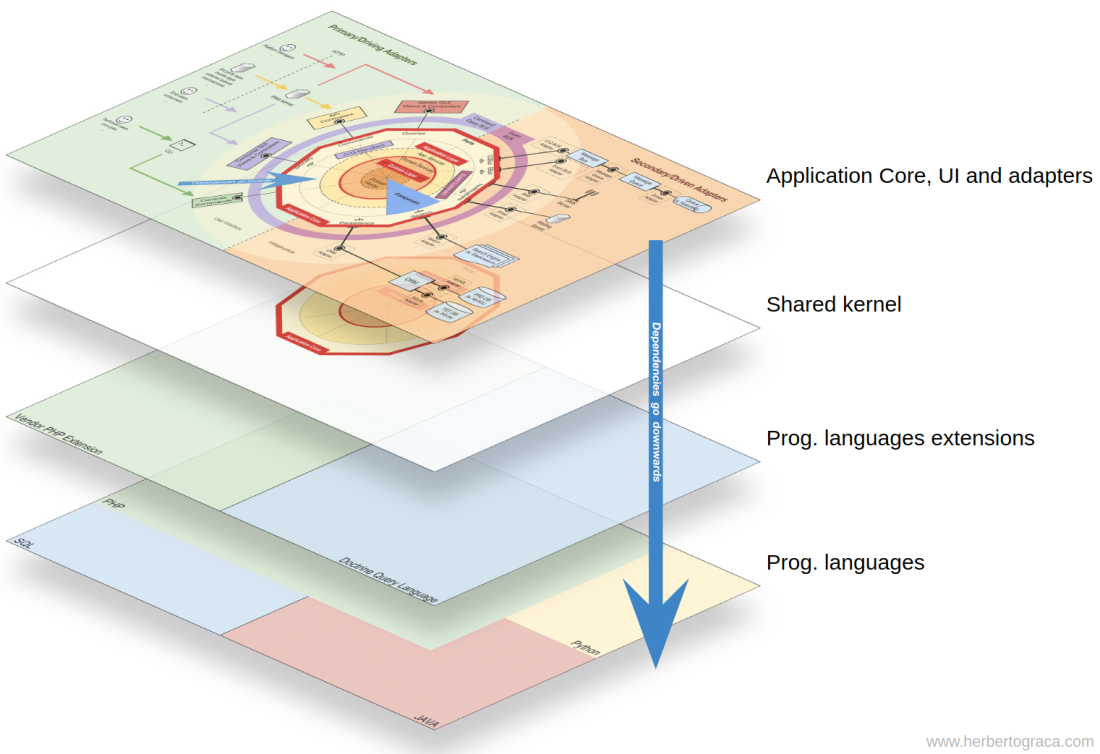
Explicit Architecture is how I rationalise a set of principles and practices advocated by developers far more experienced than me and how I organise a code base to make it reflect and communicate the architecture and domain of the project.
In my previous post, I talked about how I put all those ideas together and presented some infographics and UMLish diagrams to try to create some kind of a concept map of how I think of it.
However, how do we actually put it to practice in our codebase?!
In this post, I will talk about how I reflect the architecture and the domain of a project in the code and will propose a generic structure that I think that can help us plan for maintainability.
Continue reading “Reflecting architecture and domain in code” →