This post is part of The Software Architecture Chronicles, a series of posts about Software Architecture. In them, I write about what I’ve learned on Software Architecture, how I think of it, and how I use that knowledge. The contents of this post might make more sense if you read the previous posts in this series.
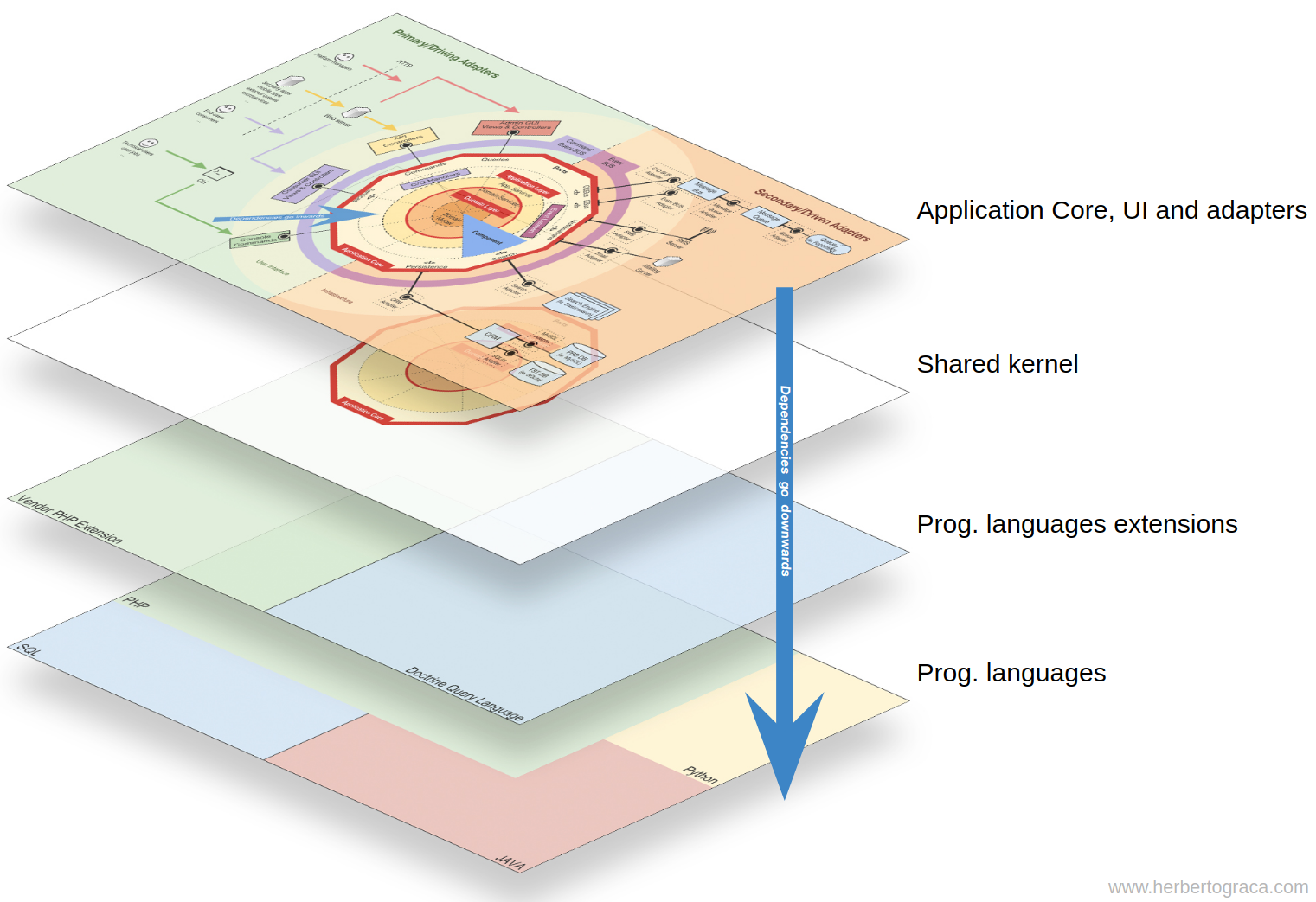
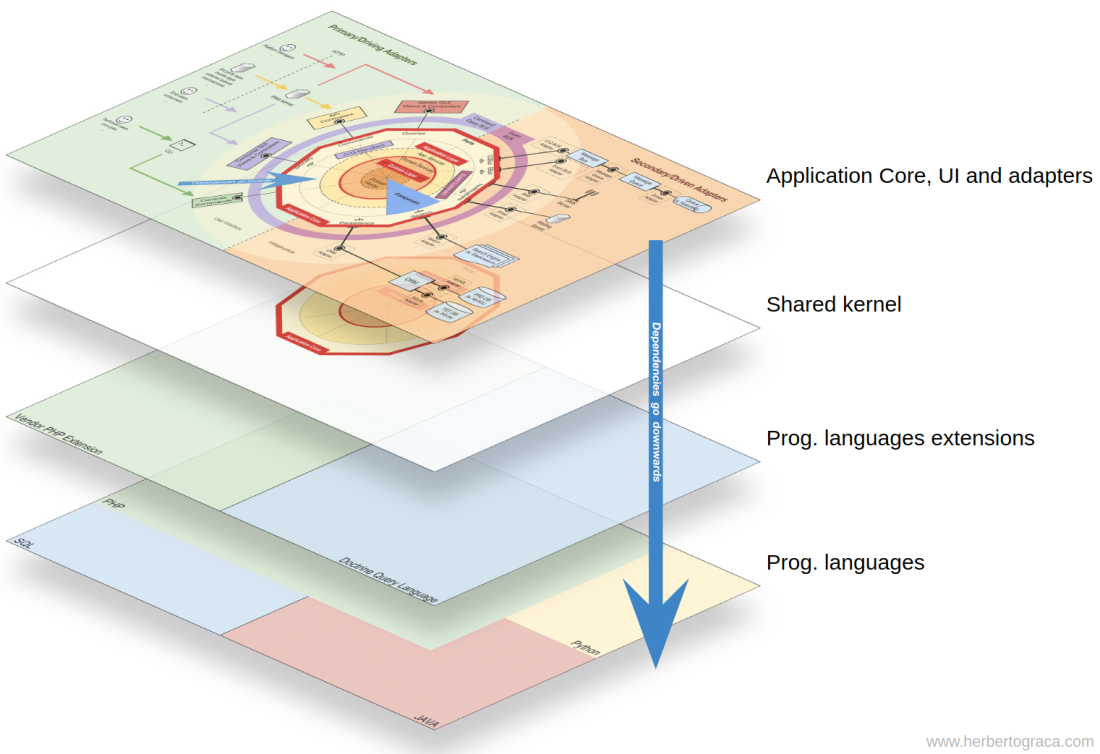
In my previous post in this series, I published an infographic that reflects the mental map I use to figure out the relationships between the code units types.
However, there was something that I always felt it was not very well reflected there, but I just didn’t know how to do it any better: the shared kernel.
Furthermore, I figured out a few more things, and I’m gonna write about it all in this post!
Looking at the infographic I published in my last post of this series, we see the shared kernel in the very centre of the diagram, looking like it is within the Domain layer and above the conic sections that represent bounded contexts.
Despite its location, I did not mean to imply that the shared kernel depends on the remainder of the code nor that the shared kernel is another layer within the Domain layer.
What is the shared kernel?!
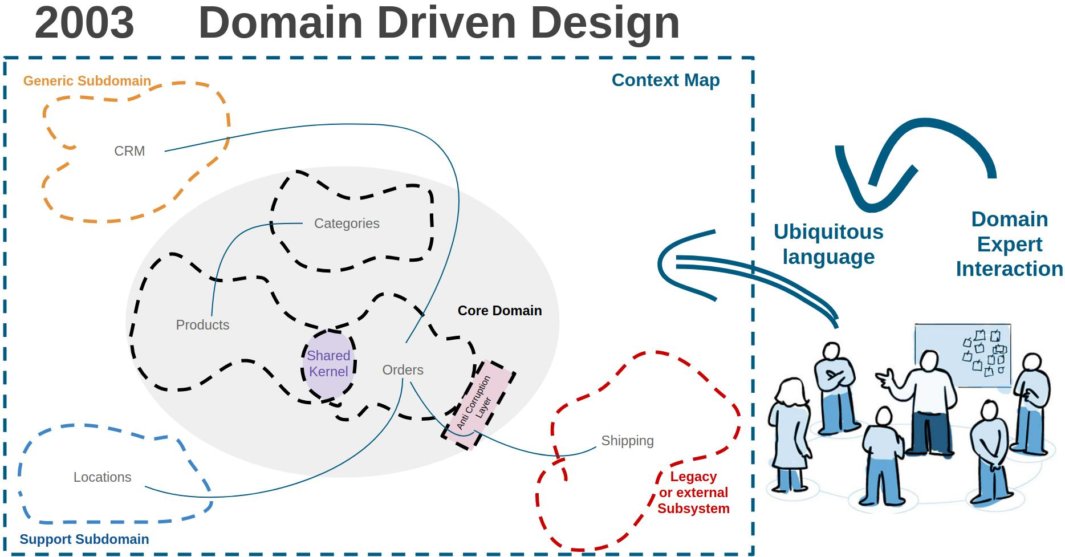
The shared kernel as defined by Eric Evans, the father of DDD, is the code that the development team decides to share between several bounded contexts:
[…] some subset of the domain model that the two teams agree to share. Of course this includes, along with this subset of the model, the subset of code or of the database design associated with that part of the model. This explicitly shared stuff has special status, and shouldn’t be changed without consultation with the other team.
Shared Kernel, DDD wiki by Ward Cunningham
So basically, it can be any type of code: domain layer code, application layer code, libraries, … whatever.
In the context of the mental map I use, however, I think of it as a subset of that, as specific types of code. In my mental map, the shared kernel contains the domain and application layers code that is shared among bounded contexts in order for communication between bounded contexts to be possible.
This means, for example, the events that are triggered in one or more bounded contexts and listened to within other bounded contexts. Together with those events we need to share all data types that are used by those events, for example: entities IDs, value objects, enums, etc. Complex objects like entities should not be used by events directly because they can be problematic to serialize/unserialize into/from a queue, so the shared code shouldn’t propagate much.
Of course that if we have in our hands a polyglot system, composed of micro-services developed in different languages, this shared kernel needs to be descriptive, in json, xml, yaml, or whatever, so that all micro-services can understand it.
As a result, this shared kernel is completely decoupled from the remainder of the codebase, from the components. This is great, as it means that the components, although coupled to the shared kernel, are decoupled between each other. The shared code is explicitly identified and easily extractable to a separate library.
This is also quite handy if and when we decide to extract one of the bounded contexts into a micro-service separated from the monolith, we know exactly what is shared and we can simply extract the shared kernel into a library to be installed in both the monolith and the micro-service.
So to recap, in my mental map, the application core depends on the shared kernel which contains code, from the domain and application layers, that is shared between bounded contexts.
When the language is insufficient…
So, we have the application code with all its concentric layers, and the application core depends on the shared kernel, which sits below all that code.
We can also say that all that code depends on the programming language(s) being used, but that is such an obvious fact that we tend to completely ignore it.
I am bringing it up, however, because of the question “what do we do when the language constructs are not enough?!”. Well, obviously we create those language constructs ourselves and thus compensate for the language flaws. But the important follow up questions I have are “How do we transmit the rationale behind that code existence? Where do we place it? How do we make explicit when and how it should be used?”.
What I’ve seen, and done myself, is a package called Utils or Commons where that code is placed. But this ends up being a bucket where we dump all the code that we don’t know where to put! All kind of different code, with different purposes and usability (wrapped in an adapter, used directly, …) ends up being dumped there, the package has no conceptual meaning, no consistency, no cohesion, no explicitness, plenty of ambiguity.
I want to abolish the Utils and Commons packages!
All packages must have conceptual cohesion! When and how a package is to be used must be explicit! There must be no ambiguity!
So, for example, if our application has some special way to interact with the CLI, instead of placing it in a namespace ‘Acme/Util/SpecialCli’ we can put it into ‘Acme/App/Infrastructure/Cli/SpecialCli’ which tells us that this package is about the CLI, it is part of the infrastructure of the application ‘App’ of company ‘Acme’. Being part of the App infrastructure also tells us that there is a port, in the application core, to which this package complies to.
Alternatively, if we see this package as something that the language itself should/could have, we can place it in a namespace that reflects that, for example ‘Acme/PhpExtension/SpecialCli’. This tells us that this package should be seen as part of the language itself, and therefore its code should be used directly in the codebase as any language construct. Of course, however, if another company depends on this package it might be wise for them not to depend directly on it, it is safer to create a port/adapter so they can swap it for something else, but if we own the package we can decide to treat it as part of the language as the risk of needing to swap it for another alternative is not that much. It’s always about the tradeoffs.
Another example of something I could consider part of the language would be UUIDs in PHP. I can imagine it is not part of the language because there is a new version every once in a while and it would be a maintainability burden, but otherwise it would be a concept generic, widespread and consistent enough to be part of the language.
So, why not create an implementation of UUIDs and use it as if it was part of PHP itself, just like we use a DateTime object?! As long as we control the implementation, I can see no down side to it.
What about Doctrine Query Language (DQL) ? (Doctrine is a port of Hibernate into PHP) Can we treat DQL as if it was SQL, Elasticsearch QL, or Mongo QL?
Conclusion
So in conclusion, I see these 4 major types of code at the macro level, and I think making them explicit in the code organization can be key for us to stop ending up with a big ball of mud.
What, for me, is an unquestionable truth is that the architecture will always be there, the only question is: are we in control of it or not?!
So let’s explicitly organize the code so it helps communicate the architecture, follow my mental map fully or partially, follow your own mental map, or follow someone else’s mental map, but please let’s use some consistent reasoning to organise the code and make the project explicitly communicate its architecture using its structure, its code organisation.

First of all congratulations for the post, great content. But some points caught my attention!
Let’s suppose an application uses Onion Architecture and DDD
“Direction of coupling is toward the center” is an Onion Concept
Shared Kernel is an DDD concept
But, use a Shared Kernel in an Onion Architecture will make my core layers change the direction of coupling, for example:
Domain Model or Domain Services will reference the Shared Kernel, this way the direction of coupling will invert
It will not break one of the main rules of onion architecture?
Thank you so much!
Best Regards
LikeLike
There’s no reason for the dependency direction to go outwards. As i tried to show with the diagram, i see the shared kernel below, not outside. So if a code unit belongs in the domain model but also in the shared kernel, i see it below and still inwards regarding the application layer. So the dependencies direction still goes inwards.
LikeLike
Sorry for my my mistake, i Misunderstood some points!
Now I got it!
Thank for your attention and patience, you are helping me a lot!
Best Regards!
LikeLike
Super! 🙂
LikeLike
Thank you, Herberto,
I really enjoy your chonicles and I learn alot from them.
Best,
LikeLike
Tkx man! 🙂
LikeLike
Hello Herberto,
I have a question if you can please help me, I did a project on Symfony 2.7 and Doctrine, In this project I have controllers that access the services and the services access the repositories and some factories, I will say that this services are a mix of application service and domain service, I understand the importance of separating them, I don’t know if it’s wise to refactor them at this stage (I am not planning on refactoring everything just the services), the project is growing and my concern is that it becomes unmanageable in the future. What should I look for to make this decision?
Thank you very much,
Gaston
LikeLike
I would check the ratio of ciclomatic complexity x historic change rate.
In other words, refactor the most complex code units, who were changed more often in the last 3 (?) months. If u still need to filter from those, choose the ones u predict will have more changes in the short term.
I even did a small CLI app to calculate this some time ago, u can find it in my github account. (I would post it but im in the tram now)
Hope this helps.
LikeLiked by 1 person
Many thanks for your advice and time it surely help me, I will look for your CLI.
Best,
Gaston
LikeLike
Hi hgraca, of course, respect is the key in human relationships, no need to fight 🙂 just saying each one vision about the subject. It is cool to talk about these things and see what other persons think. Personally, concerning to domain events, I think that they are domain objects like any other (entities, value objects, …), so they shouldn’t be exposed outside the BC where they belong. An adapter should convert them into/from messages (like DTOs) of message queue (rabbitMQ for example). I wouldn’t put domain events in a shared kernel. Regards, Juan.
LikeLiked by 1 person
Hi herberto. I don’t think shared kernel has application layer too. It is just a model with concepts shared by several BCs, along with the persistence stuff if necessary. What you defined as a shared kernel is more like a library with things used in DDD projects, like domain events, ids, and so on, and there you can have common things used in application layer too. But it is just a common library, not a shared kernel.
Regards, Juan.
LikeLike
The Shared Kernel is in no way restricted to the Domain layer, is simply the code shared by 2 bounded contexts (check the transcription in the post and note that “domain model” is different than “domain layer”).
An event which is triggered and listened to in the application layer needs to be shared among bounded contexts, therefore not only the domain layer is in the subset of Shared Kernel that I mention.
Putting it in a library or not, is irrelevant and depends on the concrete case at hand.
LikeLike
Hello Herberto. I don’t agree (as almost always) with some things you say in your reply, but I’m so tired of discussing about the meaning of some concepts… it was my fault to write the comment, it would be better that I didn’t say anything. Although I don’t agree with you in many things, I consider your articles are great. So, congratulations for your great work.
Best regards,
Juan.
LikeLike
Its ok man, you are respectful when disagreeing so i don’t take it in a bad way.
All the best 🙂
LikeLike