This post is part of The Software Architecture Chronicles, a series of posts about Software Architecture. In them, I write about what I’ve learned about Software Architecture, how I think of it, and how I use that knowledge. The contents of this post might make more sense if you read the previous posts in this series.
After graduating from University I followed a career as a high school teacher until a few years ago I decided to drop it and become a full-time software developer.
From then on, I have always felt like I need to recover the “lost” time and learn as much as possible, as fast as possible. So I have become a bit of an addict in experimenting, reading and writing, with a special focus on software design and architecture. That’s why I write these posts, to help me learn.
In my last posts, I’ve been writing about many of the concepts and principles that I’ve learned and a bit about how I reason about them. But I see these as just pieces of big a puzzle.
Today’s post is about how I fit all of these pieces together and, as it seems I should give it a name, I call it Explicit Architecture. Furthermore, these concepts have all “passed their battle trials” and are used in production code on highly demanding platforms. One is a SaaS e-com platform with thousands of web-shops worldwide, another one is a marketplace, live in 2 countries with a message bus that handles over 20 million messages per month.
- Fundamental blocks of the system
- Tools
- Connecting the tools and delivery mechanisms to the Application Core
- Application Core Organisation
- Components
- Flow of control
Fundamental blocks of the system
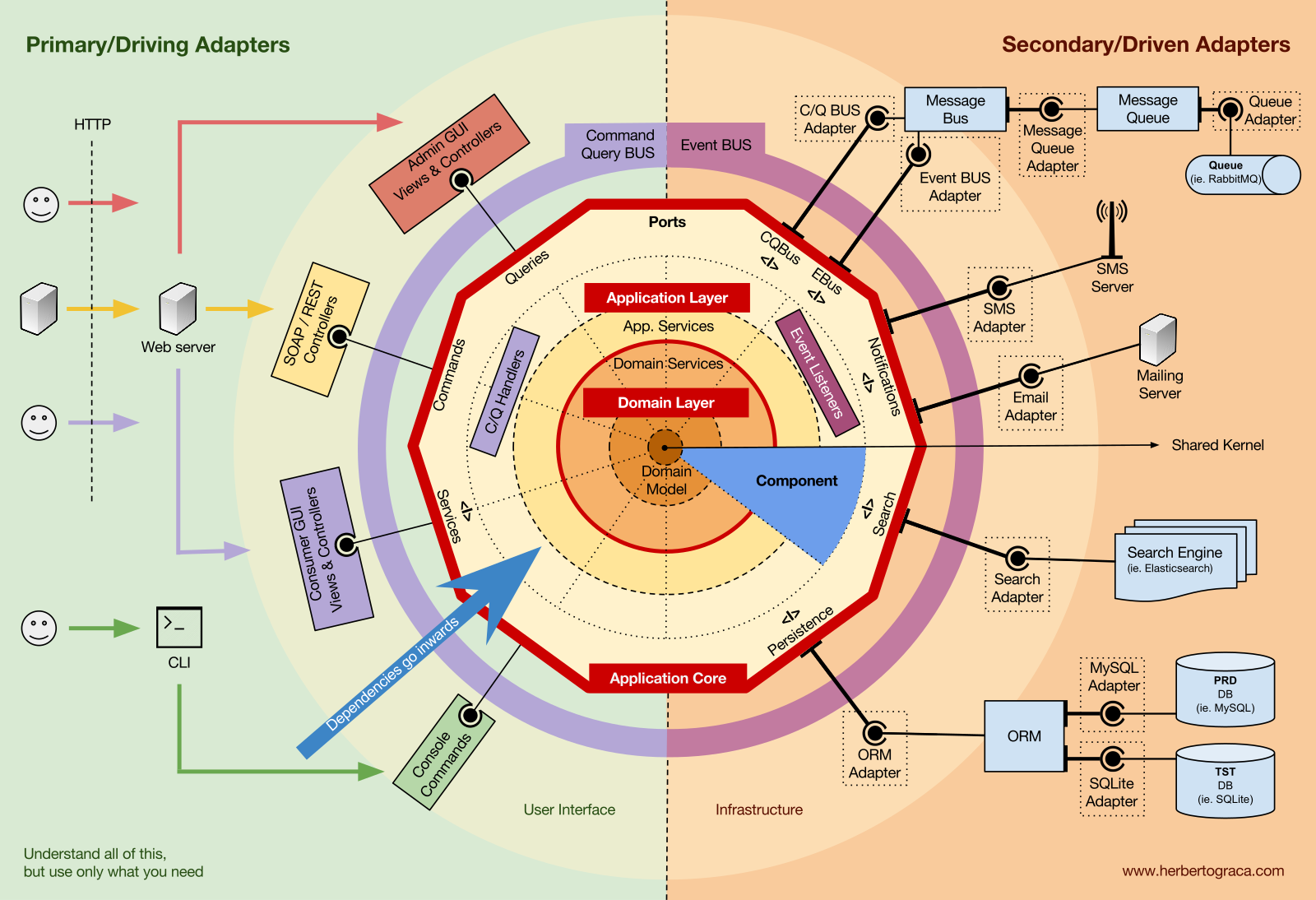
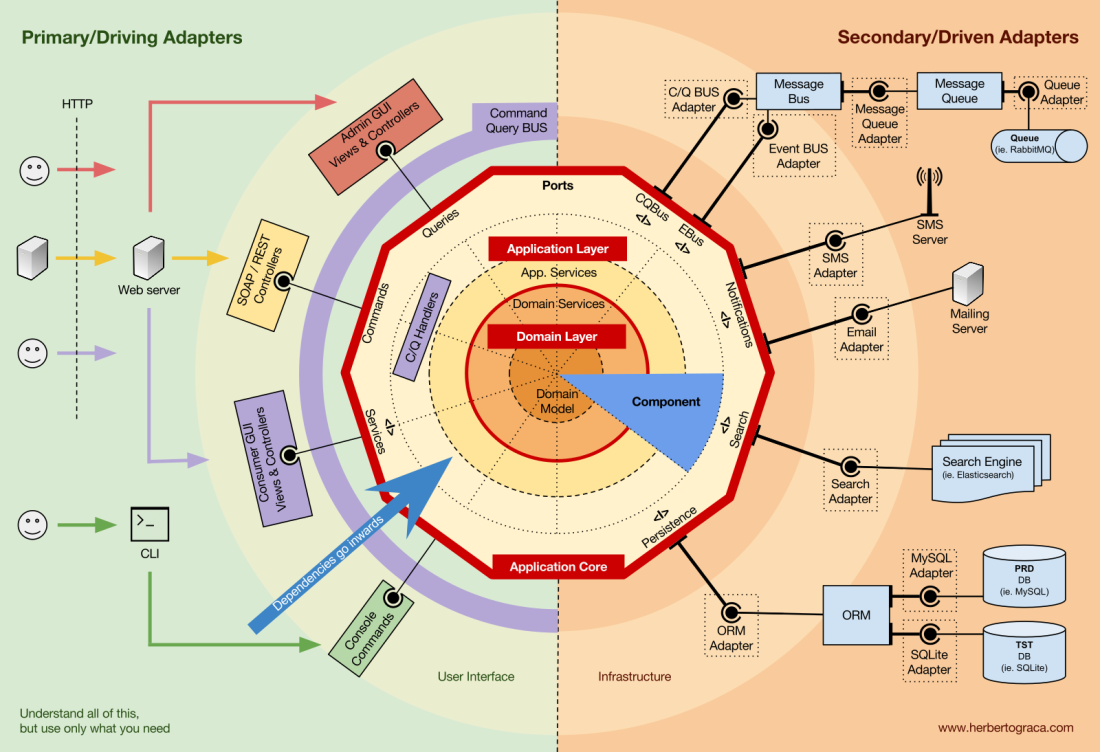
I start by recalling EBI and Ports & Adapters architectures. Both of them make an explicit separation of what code is internal to the application, what is external, and what is used for connecting internal and external code.
Furthermore, Ports & Adapters architecture explicitly identifies three fundamental blocks of code in a system:
- What makes it possible to run a user interface, whatever type of user interface it might be;
- The system business logic, or application core, which is used by the user interface to actually make things happen;
- Infrastructure code, that connects our application core to tools like a database, a search engine or 3rd party APIs.
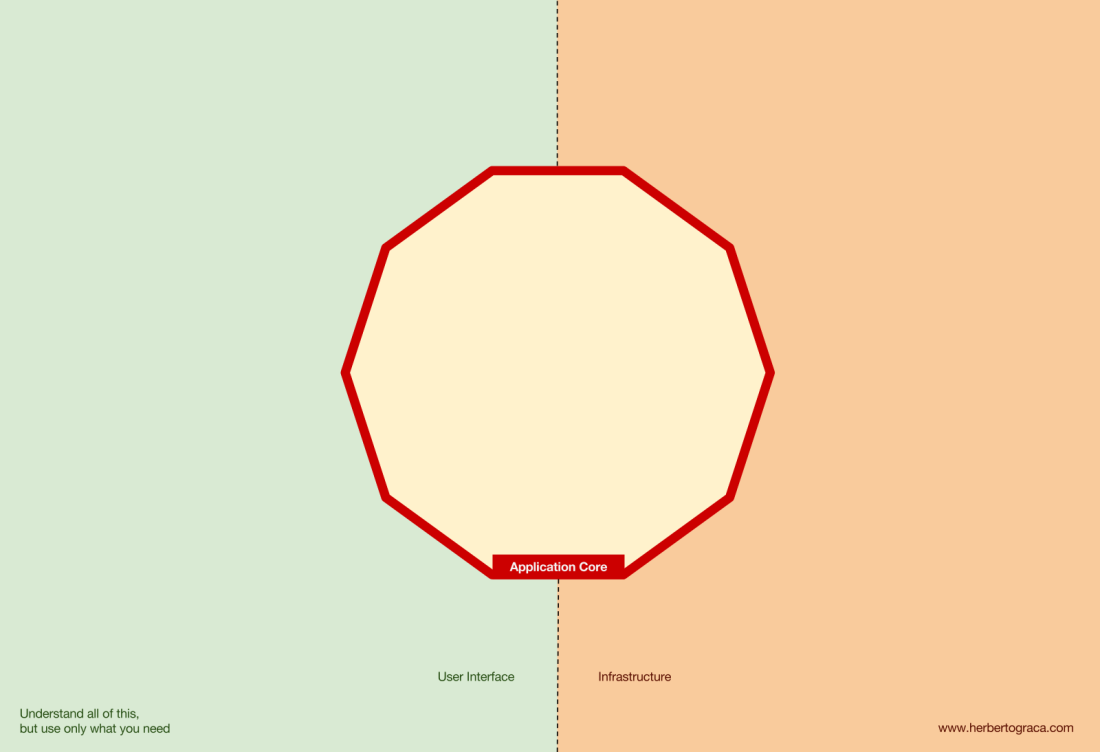
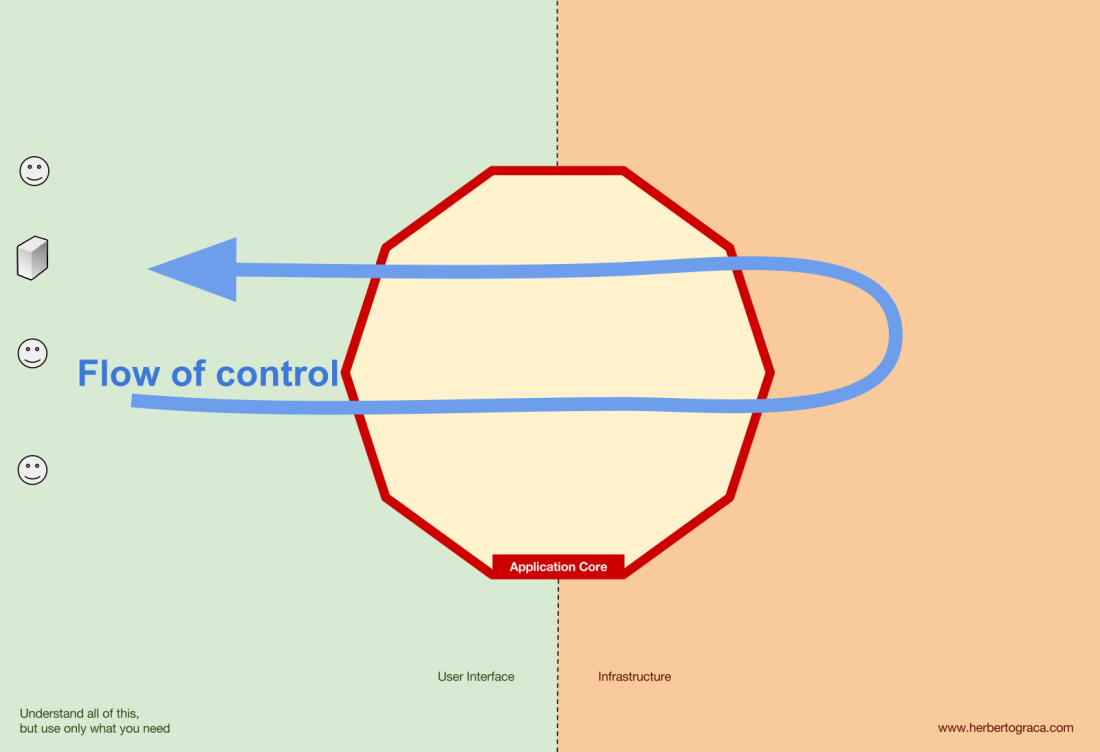
The application core is what we should really care about. It is the code that allows our code to do what it is supposed to do, it IS our application. It might use several user interfaces (progressive web app, mobile, CLI, API, …) but the code actually doing the work is the same and is located in the application core, it shouldn’t really matter what UI triggers it.
As you can imagine, the typical application flow goes from the code in the user interface, through the application core to the infrastructure code, back to the application core and finally deliver a response to the user interface.
Tools
Far away from the most important code in our system, the application core, we have the tools that our application uses, for example, a database engine, a search engine, a Web server or a CLI console (although the last two are also delivery mechanisms).
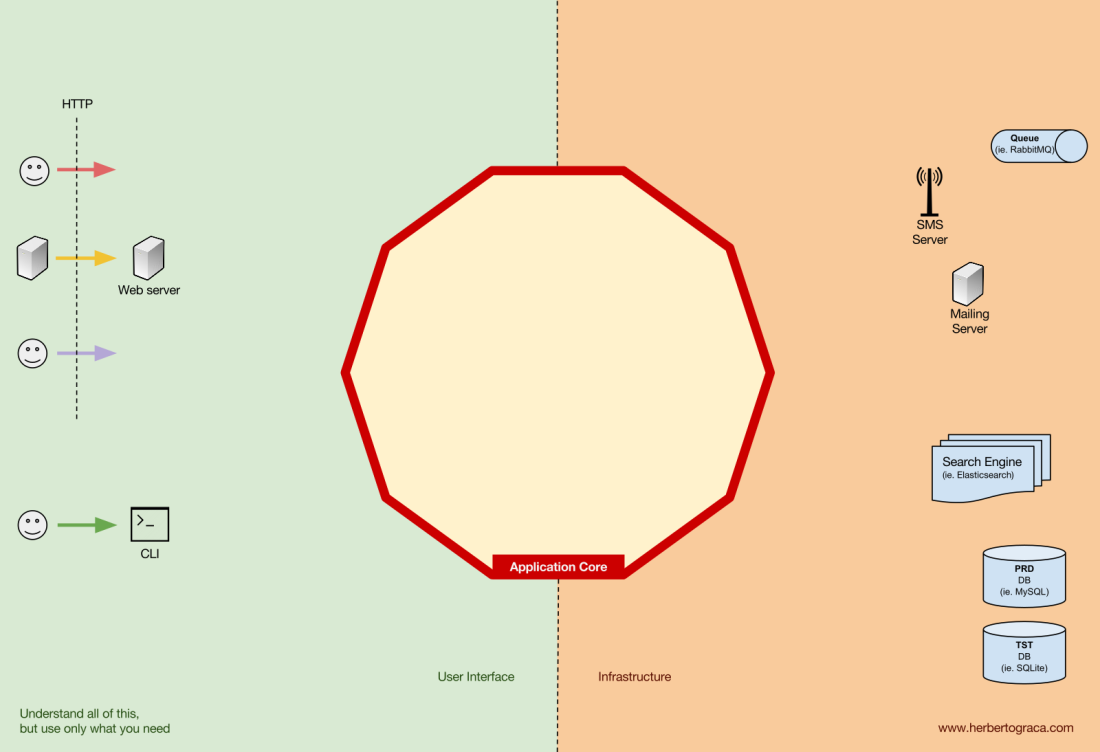
While it might feel weird to put a CLI console in the same “bucket” as a database engine, and although they have different types of purposes, they are in fact tools used by the application. The key difference is that, while the CLI console and the web server are used to tell our application to do something, the database engine is told by our application to do something. This is a very relevant distinction, as it has strong implications on how we build the code that connects those tools with the application core.
Connecting the tools and delivery mechanisms to the Application Core
The code units that connect the tools to the application core are called adapters (Ports & Adapters Architecture). The adapters are the ones that effectively implement the code that will allow the business logic to communicate with a specific tool and vice-versa.
The adapters that tell our application to do something are called Primary or Driving Adapters while the ones that are told by our application to do something are called Secondary or Driven Adapters.
Ports
These Adapters, however, are not randomly created. They are created to fit a very specific entry point to the Application Core, a Port. A port is nothing more than a specification of how the tool can use the application core, or how it is used by the Application Core. In most languages and in its most simple form, this specification, the Port, will be an Interface, but it might actually be composed of several Interfaces and DTOs.
It’s important to note that the Ports (Interfaces) belong inside the business logic, while the adapters belong outside. For this pattern to work as it should, it is of utmost importance that the Ports are created to fit the Application Core needs and not simply mimic the tools APIs.
Primary or Driving Adapters
The Primary or Driver Adapters wrap around a Port and use it to tell the Application Core what to do. They translate whatever comes from a delivery mechanism into a method call in the Application Core.

In other words, our Driving Adapters are Controllers or Console Commands who are injected in their constructor with some object whose class implements the interface (Port) that the controller or console command requires.
In a more concrete example, a Port can be a Service interface or a Repository interface that a controller requires. The concrete implementation of the Service, Repository or Query is then injected and used in the Controller.
Alternatively, a Port can be a Command Bus or Query Bus interface. In this case, a concrete implementation of the Command or Query Bus is injected into the Controller, who then constructs a Command or Query and passes it to the relevant Bus.
Secondary or Driven Adapters
Unlike the Driver Adapters, who wrap around a port, the Driven Adapters implement a Port, an interface, and are then injected into the Application Core, wherever the port is required (type-hinted).
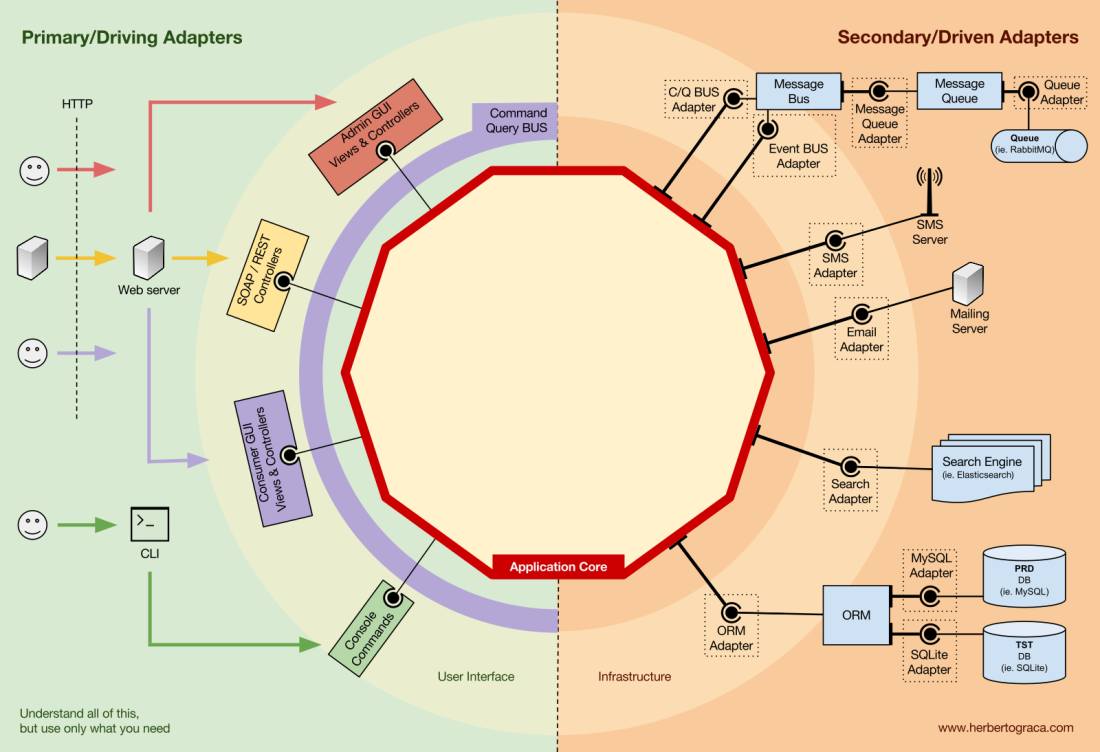
For example, let’s suppose that we have a naive application which needs to persist data. So we create a persistence interface that meets its needs, with a method to save an array of data and a method to delete a line in a table by its ID. From then on, wherever our application needs to save or delete data we will require in its constructor an object that implements the persistence interface that we defined.
Now we create an adapter specific to MySQL which will implement that interface. It will have the methods to save an array and delete a line in a table, and we will inject it wherever the persistence interface is required.
If at some point we decide to change the database vendor, let’s say to PostgreSQL or MongoDB, we just need to create a new adapter that implements the persistence interface and is specific to PostgreSQL, and inject the new adapter instead of the old one.
Inversion of control
A characteristic to note about this pattern is that the adapters depend on a specific tool and a specific port (by implementing an interface). But our business logic only depends on the port (interface), which is designed to fit the business logic needs, so it doesn’t depend on a specific adapter or tool.
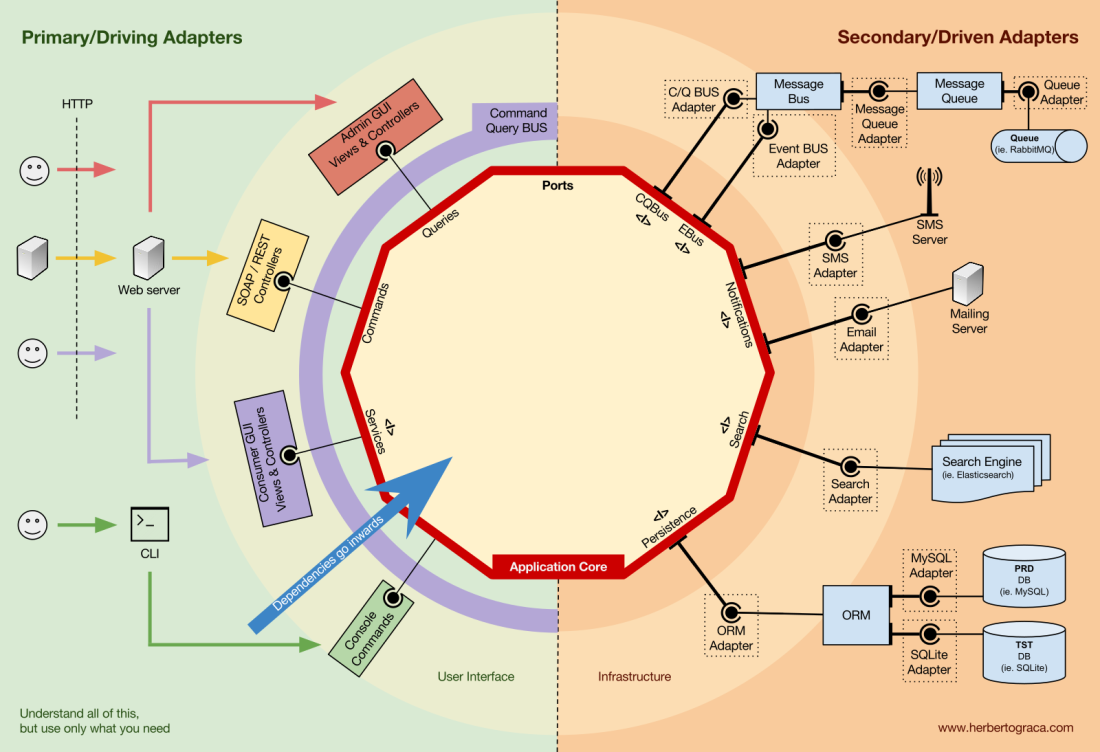
This means the direction of dependencies is towards the centre, it’s the inversion of control principle at the architectural level.
Although, again, it is of utmost importance that the Ports are created to fit the Application Core needs and not simply mimic the tools APIs.
Application Core organisation
The Onion Architecture picks up the DDD layers and incorporates them into the Ports & Adapters Architecture. Those layers are intended to bring some organisation to the business logic, the interior of the Ports & Adapters “hexagon”, and just like in Ports & Adapters, the dependencies direction is towards the centre.
Application Layer
The use cases are the processes that can be triggered in our Application Core by one or several User Interfaces in our application. For example, in a CMS we could have the actual application UI used by the common users, another independent UI for the CMS administrators, another CLI UI, and a web API. These UIs (applications) could trigger use cases that can be specific to one of them or reused by several of them.
The use cases are defined in the Application Layer, the first layer provided by DDD and used by the Onion Architecture.
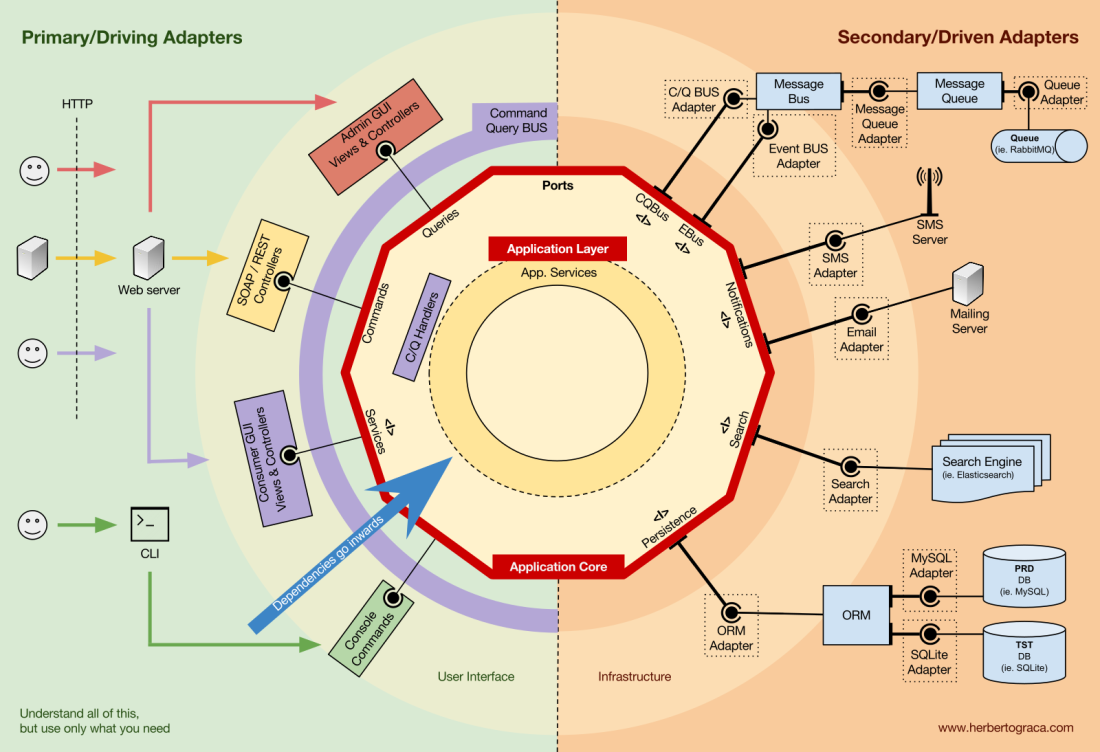
This layer contains Application Services (and their interfaces) as first class citizens, but it also contains the Ports & Adapters interfaces (ports) which include ORM interfaces, search engines interfaces, messaging interfaces and so on. In the case where we are using a Command Bus and/or a Query Bus, this layer is where the respective Handlers for the Commands and Queries belong.
The Application Services and/or Command Handlers contain the logic to unfold a use case, a business process. Typically, their role is to:
- use a repository to find one or several entities;
- tell those entities to do some domain logic;
- and use the repository to persist the entities again, effectively saving the data changes.
The Command Handlers can be used in two different ways:
- They can contain the actual logic to perform the use case;
- They can be used as mere wiring pieces in our architecture, receiving a Command and simply triggering logic that exists in an Application Service.
Which approach to use depends on the context, for example:
- Do we already have the Application Services in place and are now adding a Command Bus?
- Does the Command Bus allow specifying any class/method as a handler, or do they need to extend or implement existing classes or interfaces?
This layer also contains the triggering of Application Events, which represent some outcome of a use case. These events trigger logic that is a side effect of a use case, like sending emails, notifying a 3rd party API, sending a push notification, or even starting another use case that belongs to a different component of the application.
Domain Layer
Further inwards, we have the Domain Layer. The objects in this layer contain the data and the logic to manipulate that data, that is specific to the Domain itself and it’s independent of the business processes that trigger that logic, they are independent and completely unaware of the Application Layer.
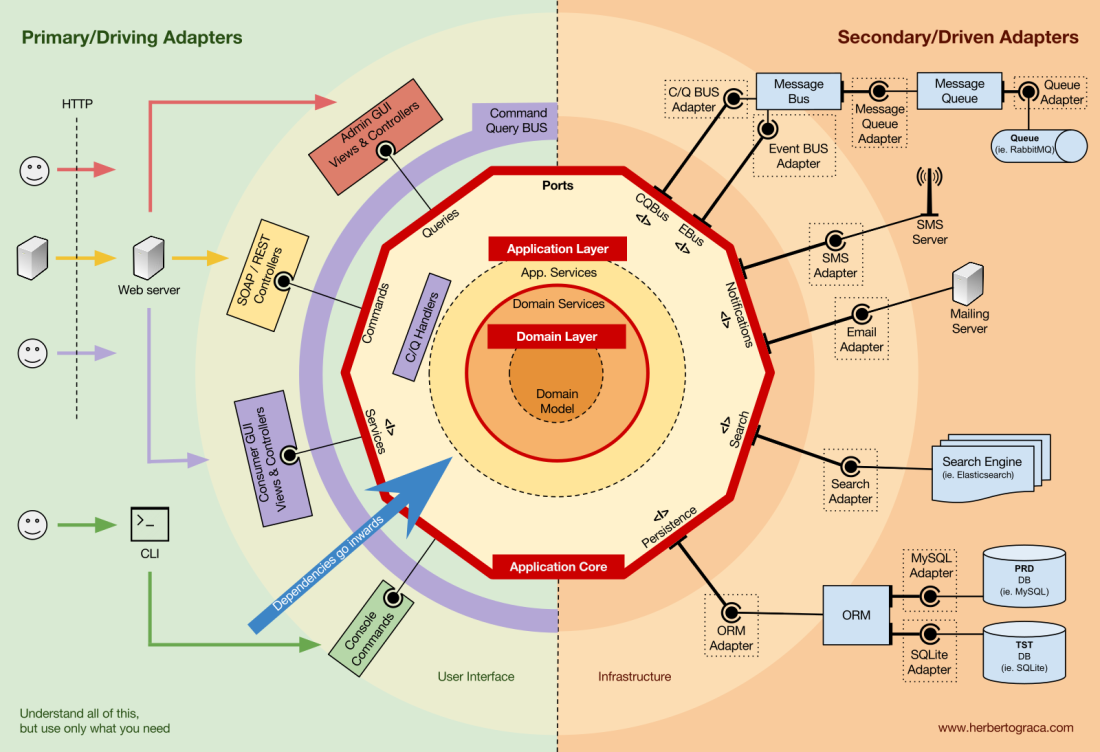
Domain Services
As I mentioned above, the role of an Application Service is to:
- use a repository to find one or several entities;
- tell those entities to do some domain logic;
- and use the repository to persist the entities again, effectively saving the data changes.
However, sometimes we encounter some domain logic that involves different entities, of the same type or not, and we feel that that domain logic does not belong in the entities themselves, we feel that that logic is not their direct responsibility.
So our first reaction might be to place that logic outside the entities, in an Application Service. However, this means that that domain logic will not be reusable in other use cases: domain logic should stay out of the application layer!
The solution is to create a Domain Service, which has the role of receiving a set of entities and performing some business logic on them. A Domain Service belongs to the Domain Layer, and therefore it knows nothing about the classes in the Application Layer, like the Application Services or the Repositories. In the other hand, it can use other Domain Services and, of course, the Domain Model objects.
Domain Model
In the very centre, depending on nothing outside it, is the Domain Model, which contains the business objects that represent something in the domain. Examples of these objects are, first of all, Entities but also Value Objects, Enums and any objects used in the Domain Model.
The Domain Model is also where Domain Events “live”. These events are triggered when a specific set of data changes and they carry those changes with them. In other words, when an entity changes, a Domain Event is triggered and it carries the changed properties new values. These events are perfect, for example, to be used in Event Sourcing.
Components
So far we have been segregating the code based on layers, but that is the fine-grained code segregation. The coarse-grained segregation of code is at least as important and it’s about segregating the code according to sub-domains and bounded contexts, following Robert C. Martin ideas expressed in screaming architecture. This is often referred to as “Package by feature” or “Package by component” as opposed to”Package by layer“, and it’s quite well explained by Simon Brown in his blog post “Package by component and architecturally-aligned testing“:



I am an advocate for the “Package by component” approach and, picking up on Simon Brown diagram about Package by component, I would shamelessly change it to the following:
These sections of code are cross-cutting to the layers previously described, they are the components of our application. Examples of components can be Authentication, Authorization, Billing, User, Review or Account, but they are always related to the domain. Bounded contexts like Authorization and/or Authentication should be seen as external tools for which we create an adapter and hide behind some kind of port.
Decoupling the components
Just like the fine-grained code units (classes, interfaces, traits, mixins, …), also the coarsely grained code-units (components) benefit from low coupling and high cohesion.
To decouple classes we make use of Dependency Injection, by injecting dependencies into a class as opposed to instantiating them inside the class, and Dependency Inversion, by making the class depend on abstractions (interfaces and/or abstract classes) instead of concrete classes. This means that the depending class has no knowledge about the concrete class that it is going to use, it has no reference to the fully qualified class name of the classes that it depends on.
In the same way, having completely decoupled components means that a component has no direct knowledge of any another component. In other words, it has no reference to any fine-grained code unit from another component, not even interfaces! This means that Dependency Injection and Dependency Inversion are not enough to decouple components, we will need some sort of architectural constructs. We might need events, a shared kernel, eventual consistency, and even a discovery service!
Triggering logic in other components
When one of our components (component B) needs to do something whenever something else happens in another component (component A), we can not simply make a direct call from component A to a class/method in component B because A would then be coupled to B.
However we can make A use an event dispatcher to dispatch an application event that will be delivered to any component listening to it, including B, and the event listener in B will trigger the desired action. This means that component A will depend on an event dispatcher, but it will be decoupled from B.
Nevertheless, if the event itself “lives” in A this means that B knows about the existence of A, it is coupled to A. To remove this dependency, we can create a library with a set of application core functionality that will be shared among all components, the Shared Kernel. This means that the components will both depend on the Shared Kernel but they will be decoupled from each other. The Shared Kernel will contain functionality like application and domain events, but it can also contain Specification objects, and whatever makes sense to share, keeping in mind that it should be as minimal as possible because any changes to the Shared Kernel will affect all components of the application. Furthermore, if we have a polyglot system, let’s say a micro-services ecosystem where they are written in different languages, the Shared Kernel needs to be language agnostic so that it can be understood by all components, whatever the language they have been written in. For example, instead of the Shared Kernel containing an Event class, it will contain the event description (ie. name, properties, maybe even methods although these would be more useful in a Specification object) in an agnostic language like JSON, so that all components/micro-services can interpret it and maybe even auto-generate their own concrete implementations. Read more about this in my followup post: More than concentric layers.
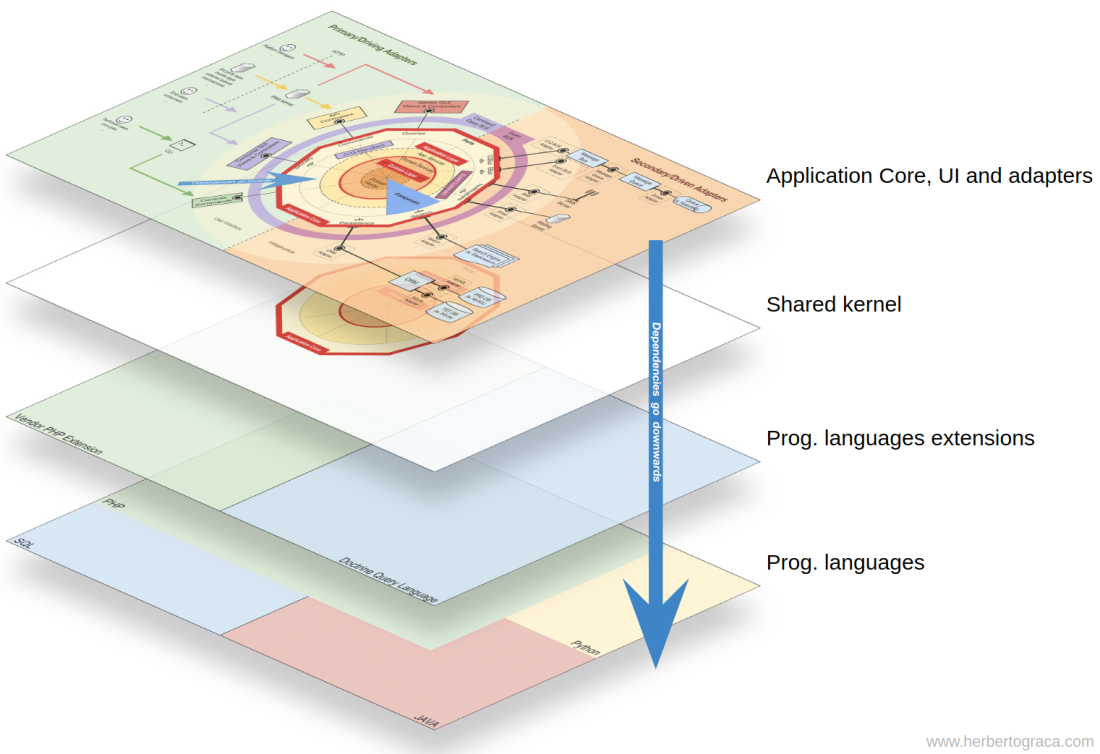
This approach works both in monolithic applications and distributed applications like micro-services ecosystems. However, when the events can only be delivered asynchronously, for contexts where triggering logic in other components needs to be done immediately this approach will not suffice! Component A will need to make a direct HTTP call to component B. In this case, to have the components decoupled, we will need a discovery service to which A will ask where it should send the request to trigger the desired action, or alternatively make the request to the discovery service who can proxy it to the relevant service and eventually return a response back to the requester. This approach will couple the components to the discovery service but will keep them decoupled from each other.
Getting data from other components
The way I see it, a component is not allowed to change data that it does not “own”, but it is fine for it to query and use any data.
Data storage shared between components
When a component needs to use data that belongs to another component, let’s say a billing component needs to use the client name which belongs to the accounts component, the billing component will contain a query object that will query the data storage for that data. This simply means that the billing component can know about any dataset, but it must use the data that it does not “own” as read-only, by the means of queries.
Data storage segregated per component
In this case, the same pattern applies, but we have more complexity at the data storage level. Having components with their own data storage means each data storage contains:
- A set of data that it owns and is the only one allowed to change, making it the single source of truth;
- A set of data that is a copy of other components data, which it can not change on its own, but is needed for the component functionality, and it needs to be updated whenever it changes in the owner component.
Each component will create a local copy of the data it needs from other components, to be used when needed. When the data changes in the component that owns it, that owner component will trigger a domain event carrying the data changes. The components holding a copy of that data will be listening to that domain event and will update their local copy accordingly.
Flow of control
As I said above, the flow of control goes, of course, from the user into the Application Core, over to the infrastructure tools, back to the Application Core and finally back to the user. But how exactly do classes fit together? Which ones depend on which ones? How do we compose them?
Following Uncle Bob, in his article about Clean Architecture, I will try to explain the flow of control with UMLish diagrams…
Without a Command/Query Bus
In the case we do not use a command bus, the Controllers will depend either on an Application Service or on a Query object.
[EDIT – 2017-11-18] I completely missed the DTO I use to return data from the query, so I added it now. Tkx to MorphineAdministered who pointed it out for me.
In the diagram above we use an interface for the Application Service, although we might argue that it is not really needed since the Application Service is part of our application code and we will not want to swap it for another implementation, although we might refactor it entirely.
The Query object will contain an optimized query that will simply return some raw data to be shown to the user. That data will be returned in a DTO which will be injected into a ViewModel. ThisViewModel may have some view logic in it, and it will be used to populate a View.
The Application Service, on the other hand, will contain the use case logic, the logic we will trigger when we want to do something in the system, as opposed to simply view some data. The Application Services depend on Repositories which will return the Entity(ies) that contain the logic which needs to be triggered. It might also depend on a Domain Service to coordinate a domain process in several entities, but that is hardly ever the case.
After unfolding the use case, the Application Service might want to notify the whole system that that use case has happened, in which case it will also depend on an event dispatcher to trigger the event.
It is interesting to note that we place interfaces both on the persistence engine and on the repositories. Although it might seem redundant, they serve different purposes:
- The persistence interface is an abstraction layer over the ORM so we can swap the ORM being used with no changes to the Application Core.
- The repository interface is an abstraction on the persistence engine itself. Let’s say we want to switch from MySQL to MongoDB. The persistence interface can be the same, and, if we want to continue using the same ORM, even the persistence adapter will stay the same. However, the query language is completely different, so we can create new repositories which use the same persistence mechanism, implement the same repository interfaces but builds the queries using the MongoDB query language instead of SQL.
With a Command/Query Bus
In the case that our application uses a Command/Query Bus, the diagram stays pretty much the same, with the exception that the controller now depends on the Bus and on a command or a Query. It will instantiate the Command or the Query, and pass it along to the Bus who will find the appropriate handler to receive and handle the command.
In the diagram below, the Command Handler then uses an Application Service. However, that is not always needed, in fact in most of the cases the handler will contain all the logic of the use case. We only need to extract logic from the handler into a separated Application Service if we need to reuse that same logic in another handler.
[EDIT – 2017-11-18] I completely missed the DTO I use to return data from the query, so I added it now. Tkx to MorphineAdministered who pointed it out for me.
You might have noticed that there is no dependency between the Bus and the Command, the Query nor the Handlers. This is because they should, in fact, be unaware of each other in order to provide for good decoupling. The way the Bus will know what Handler should handle what Command, or Query, should be set up with mere configuration.
As you can see, in both cases all the arrows, the dependencies, that cross the border of the application core, they point inwards. As explained before, this a fundamental rule of Ports & Adapters Architecture, Onion Architecture and Clean Architecture.
Conclusion
The goal, as always, is to have a codebase that is loosely coupled and high cohesive, so that changes are easy, fast and safe to make.
Plans are worthless, but planning is everything.
Eisenhower
This infographic is a concept map. Knowing and understanding all of these concepts will help us plan for a healthy architecture, a healthy application.
Nevertheless:
The map is not the territory.
Alfred Korzybski
Meaning that these are just guidelines! The application is the territory, the reality, the concrete use case where we need to apply our knowledge, and that is what will define what the actual architecture will look like!
We need to understand all these patterns, but we also always need to think and understand exactly what our application needs, how far should we go for the sake of decoupling and cohesiveness. This decision can depend on plenty of factors, starting with the project functional requirements, but can also include factors like the time-frame to build the application, the lifespan of the application, the experience of the development team, and so on.
This is it, this is how I make sense of it all. This is how I rationalize it in my head.
I expanded these ideas a bit more on a followup post: More than concentric layers.
However, how do we make all this explicit in the code base? That’s the subject of one of my next posts: how to reflect the architecture and domain, in the code.
Last but not least, thanks to my colleague Francesco Mastrogiacomo, for helping me make my infographic look nice. 🙂
Translations
- Chinese, by Qinyusuain
- Japanese, by Tagoto
- Vietnamese, by Edward Hien Hoang
- Russian, by m1rko

Hi Herberto, that’s a great quality read, thanks! At our company we use this sort of architecture a lot. I do not make any distinction between driving ports and driven ports, I also embrace the fact that a port can be bi-directional. The differentiation becomes especially blurry with asynchronous systems. Strictly speaking, “user interface” and “infrastructure” is the same thing to me, which I call “the outside”. That has worked well for us so far. Any strong argument against that?
LikeLike
Nothing against it at all 🙂
LikeLike
I’m implementing onion architecture for the first time, and my project basically follows the structure below:
DOMAIN
1) MyApp.Domain.Entities (DLL)
PagedResult.cs
ProductByProducerFilter.cs
Product.cs
2) MyApp.Domain.Interfaces (DLL)
public interface IProductRepository {
PagedResult GetProductsByProducer(ProductByProducerFilter Filter);
}
SERVICE INTERFACES
3) MyApp.Services.Interfaces (DLL)
public interface IProductService {
PagedResult GetProducts(ProductByProducerFilter Filter);
}
SERVICE
4) MyApp.Services (DLL)
public class ProductService: IProductService {
private readonly IProductRepository _Product = null;
public ProductService(IProductRepository Product) {
this._Product = Product;
}
public PagedResultGetProducts(ProductByProducerFilter Filter) {
return this._Product.GetProductsByProducer(Filter);
}
}
USER INTERFACE
5) MyApp.UI (DLL)
My User interface will use ProductService and show the content to the user
Basically I have the classes PagedResult and ProductByProducerFilter that are located in my Domain Entities, but the entities in my domain are business objects and not classes responsible for paging and filtering.
Create other DLL to keep the classes ProductByProducerFilter and PagedResult in my Domain in a way that all other layers can reference it is the best solution? How Can I deal properly with this type of situation?
Thank you so much for your attention!
Your Posts are great, congratulations!
LikeLike
If I understand correctly, u should put the pager and the filter in the application layer, your entities should not need to access them.
LikeLike
The way how i understood Onion Architecture the direction of coupling is toward the center and Domain interfaces will represent behaviors such as save and retrieve data from database.
If I put the pager and the filter in the application layer, the interface IProductRepository located in MyApp.Domain.Interfaces will need to reference to the pager and filter located in a upper layer.
This way, Am not breaking one one of the most important Onion Rules?
Thank very much!
LikeLike
Yes, you are.
However, I do not place the repositories in the domain layer, I place them in the application layer, I see them as entry/exit points to the application, on the infrastructure side (as opposed to the presentation side).
So, if you put the repositories in the application layer, there is nothing in the domain layer that needs to know about those repositories nor filters.
If those repositories need domain rules to filter entities, then I see 2 options:
1. We get a list of entities and then loop through them filtering them according to the result of a method in the entity;
2. We create a Specification object in the domain layer which will that domain rule (in SQL and any other language needed) and use it as a filter in the repository.
🙂
LikeLike
“However, the query language is completely different, so we can create new repositories which use the same persistence mechanism, implement the same repository interfaces but builds the queries using the MongoDB query language instead of SQL.”
I’m trying to understand it all, but I simply cannot wrap my head around why the repository is so strongly bound to the type of database used. In my view, shouldn’t everything inside the application core be totally unaware about the actual implementations outside the core?
LikeLike
I don’t see them as strongly bound to the type of DB used, but more as being tied to the query language used.
The query language, in the end, is at the bottom of the dependencies and at some point, our codebase needs to depend on the language itself.
That being said, we can abstract the actual query language behind something like the Doctrine query builder, but even that is not a solution for all types of persistence stores (relational DBs and similar) and then we are tied to the Doctrine query language itself anyway.
The bottom line is that having a solution that completely abstracts the codebase from all query languages, is something nearly impossible.
LikeLike
Thank you. I think I understand it better now 🙂
LikeLike
Hello, Herbert.
A question about “Triggering logic in other components” and “Getting data from other components”
What Do you think about to make A Parent component which connects two others components through Input Ports, something like ComponentC(ComponentAContract, ComponentVContract).
For example: RankingCalc (CreditHistory, AccountHistory) – here we want to calc client score to rank him (1 to 100). We use information from CreditHistory and AccountHistory to calculate the total score. So the call looks like RankingCalc.RankClient(clientId, presenter) and the internals do:
c = CreditHistory.GetOverduePaymentsCount(clientId);
b=AccountHistory.GetLastYearAvaerengeBalance(clientId);
score, error = DoSomeCalc (c,b);
if (!error) {
scoreRepository.save(score);
presenter.HandleSuccess(score)
} else {
presenter.HandleError(error)
}
LikeLike
I think this communication could be done via a Command Bus or Event Dispatcher.
LikeLike
I would say that my code is not strictly follows the Clean Arch. In Clean Architecture the UseCase(Interactor) is a Command Pattern which must not return values and it must present results calling the presenter injected into UseCase.
Is a component just a set of usecases (AddTodoUseCase, RemoveTodoUseCase, ListTodoUseCase)? If so it should not return value from method call and call a OutputPort method (e.g. presenter).
LikeLike
One thing that I have hard time figuring out is what is the difference between domain events and application events.
For example, what about a simple event in shopping application like OrderShipped – where does it belong? On one hand, it feels like a domain event which changes order status and belongs to the orders feature. Definitely something I would like to store when using event sourcing, as you suggested for domain events. On the other hand, there might be a lot of different components that need to know when order status changes, so from this perspective it looks more like an application event.
Are application events and domain events sent through the same event bus?
Thank you for this great post by the way, it is very helpful in understanding a hexagonal architecture.
LikeLike
Well, first i need to say this is my personal way of thinking about it, of rationalizing it. I saw this separation of event types in no other place, no guru said it, so it’s worth whatever it’s worth.
And again, theres is no “one boot fits all”.
That said, in your example i would see “OrderShipped” as an application event because its a business case that just happened. This can be used for an event store but might not be ideal cozz it depends on the application logic, so if u want to replay the event to reach the current entity state you will need to replay it with the logic of the application at the moment the event was triggered, which means checking out the correct code version from VCS for each event in the event store.
However, “OrderUpdated” with the specification about what fields of the “Order” entity changed and to what values, that i would see as a Domain event as it is triggered when an entity changes. We don’t know why an entity changed, we just know it changed, and to what. I think this might be ideal for an event store cozz its independent of logic changes.
On another hand, if the current state is wrong cozz there is a bug in the logic, and u want to fix the bug and replay the events to get the correct state… then you will want to have an event store made out of application events…
Its complex stuff, very interesting to think and talk about but also frustrating cozz i don’t have all the answers 😦
Most likely it depends on the context, on your project actual needs and on the risks the project owner/lead is willing to accept.
Hope this made it a bit more clear.
LikeLike
It is definitely more clear now which type of event is what, so thank you for taking time to respond.
However, with your definition I would argue that application events makes much more sense to be used with event sourcing than domain events 🙂 . I’ve often read that when doing event sourcing, it’s better to store a business events instead of a entity field changes and I can agree with that. For auditing purposes (which ES seems to be a good fit for) we very much want to know what happened and not just which fields have changed.
I also think that storing application events is more resilient to code changes – what if some entity field used to be a boolean flag and now we want to store it as an enum. With events that contain specific field changes, we have to create a new version of the event and either handle old version in our code, or migrate existing events. With application events, since we don’t store any specific entity fields, we can just change the “Apply” logic, throw away existing read model, and recreate it from scratch using the event stream.
Now that I think about it (if I understood correctly), what you call application events is very similar to what Greg Young call domain events, so expect more confusion to come 🙂 – http://codebetter.com/gregyoung/2010/04/11/what-is-a-domain-event/
LikeLike
Well, i dont agree with your data type and format reasoning cozz these events showld be stored in a schemaless data store like mongodb or kafka.
However, i can agree with everything else you said.
🙂
LikeLike
Wow! I have got a great experience from this article. Can Anyone please compare this with Microservices architecture?
LikeLike
This is about separating your application by components, which are domain wise modules of the application, the DDD bounded contexts.
It is exactly the same goal when we have microservices. Each microservice represents a bounded context.
LikeLike
Very good reading, thank you!
LikeLike
First of all thank you for a very interesting article, I just wish I had the knowledge gained from it a couple of years back ;)!
I have a question regarding driven ports and the domain model, I have tried designing the ports (interfaces(I’m using C#)) to not depend on the domain model but not sure this is correct?
I have tried to follow your advise on package by component so I have Component projects that depend on the Port project which makes it impossible for the interfaces defined in the Ports project to have references to any of the Component projects (cyclic dependency).
I got into trouble when a use case like “Send X to a external actor” where X is a class defined in the domain model. I could define the port(interface in C#) to be “void Send(X x);” but that would give me a cyclic dependency (Port depend on ComponentX and ComponentX depend on Port).
Another way to solve this is to define the port the same way I have solved Persistance Port “void Send(Y y);”. Here Y is something defined in SharedKernel and all domain models has Y as base class. What I don’t like about this solution is that the Send Port gets way to generic when it’s not supposed to do anything else then Send(x)..
A third way to solve this is to move this Port definition into ComponentX but that would (as I have understood it) break Package by Component idea…
Any thoughts on this is highly appreciated!
LikeLike
Hi, sorry for the late reply.
The Ports should reflect what your application core needs, but they should indeed not depend on the application core, and they should be usable by any component.
Since the ports are specific to the application core, they should be in the same repo, you shouldn’t try to reuse them in different projects, although i do understant why it is appealing to do so.
The components can depend on the port, that is how it should be. But neither the components not the ports should depend on adapters. In your example “void Send(X x);” maybe you should not depend on that X object but instead depend on an interface (from the shared kernel) or finer grained data.
Indeed i would avoid breaking package by component.
Hope thus helped, and again i apologize for taking so long to reply.
LikeLike
Firstl of all, NO need to apologize for taking your time to respond I am very great full that you take the time to reason with me on this topic!
Your answer is spot on and your suggested solution is about the same as what I did with the persistence port just never realized I could (of course) design some interface in the shared kernel specific for this port… Thank you for showing me the light 🙂
About sharing ports, I totally agree with you and that was never my intention. Just wanted to organize the code in a way to “protect” the intended architecture (making it harder to break the hexagon pattern).
The code is available here if anyone are interested in a C# implementation of this article (of course there can be many other possible solutions in C#, this is how I put it together and its work in progress): https://github.com/ForsetiSWE/VF
LikeLike
I have a system build with the Hexagon architecture (Ports and adapters). My system’s overall implementation is fine thought i am having trouble when trying to initiate two Adapters for the same port and inject them (via DI) in my use case to execute. My goal is this: the Hexagon defines a Port via an Interface IBoarding that adapters (Application adapters) implement in order for my use case to be able to communicate with two other different applications. But there is no way to Register the 2 adapters on a container ( i.e simple injector ) and find a way to inject either both when i want my use case to write to both other apps or only one of them when i want to write only to one app. Any help appreciated!!
LikeLike
Hi,
I would always inject them both, maybe lazy loaded, and use a strategy pattern to decide what to do at runtime.
LikeLike
Thank you for you answer!! Since they implement the same Interface i am registering them as a Collection in the DI container so in the use case constructor i have BoardUseCase(IEnumerable boardingadapters) ….and inside the use case i was iterating via all adapters executing the action to be performed. Any suggestions on where and how to use the strategy pattern?? Thanks in advance!
LikeLike
In each iteration you can check conditions to decide if that adapter should be used.
LikeLike
Hi Herberto,
I was thinking about @Dmitry comment above about how authorisation in a business rule context should be handled and how can this be implemented in a meaningful way. So to give an example, stackoverflow has some rules that force user to be first of all authenticated, have an active user account and to have at least 15 points to comment, 50 to answer a question, loose a point if you downvote, etc.
I would say that Authentication should be treated as a tool, of course, and that some resources should be prevented from being accessed if you are not authenticated/authorised (ex: user account) and can be configured from the firewall.
Most people do these Business Authorisation checks at the Command Handler itself or have an Application Service that will check whilst doing the rest of the action. This means that we are checking if a user is allowed to comment in the same place we are “posting a comment” or some other action.
I think business authorisation should be done using the Specification pattern : https://en.wikipedia.org/wiki/Specification_pattern so we could have single reusable complex authorisation rules before activating a specific logic so that we could check that user have posting permission
This means that not only business authorisation logic is on a Domain Service separated from the use case, but this can be reused within other use cases that could implemented same fucntionality. You actually talk about this here : “However, sometimes we encounter some domain logic that involves different entities, of the same type or not, and we feel that that domain logic does not belong in the entities themselves, we feel that that logic is not their direct responsibility.”
I would love to hear your opinion on this matter 🙂 and perhaps a better way of handling such logic
LikeLike
Hello Herberto,
Great article and juniors should learn from it)) I’m software architect and I have found so many common approaches that I have used in my projects. At the end of the day all those successful architectures for big/enterprise solutions look almost the same as you described on your diagram. There is no silver bullet and people come to that kind of Explicit Architecture which is clean, extendable and scalable.
Herberto, I would love to use that extremely beautiful drawings pattern in lectures for my students. If it is possible, can you please share it with us(your subscribers)?
LikeLike
Tkx.
Be my guest, the final image links to a google draw document, but here’s the link anyway: https://docs.google.com/drawings/d/1E_hx5B4czRVFVhGJbrbPDlb_JFxJC8fYB86OMzZuAhg/edit?usp=drive_open&ouid=114834316208200522715
LikeLike
Appreciate it!
LikeLike
Hi,
great article! I have a question. All of your query you put to query bus? Some of people use finders to get results from DB and not put them to the query bus. Finders are injected directly to the controller/command handler or other where do you need results.
Regards
LikeLike
Hi, tkx.
It depends on your needs, and human & technical resources.
The requirements drive the architecture.
So, having query objects and/or repositories is perfectly valid. I dont know exactly what you mean by finders but i suppose u refer to one of those.
However, if you have a query bus, i would stick to it, so theres ony one way of doing that in the codebase. It makes it consistent, easier to understand and change.
LikeLike
I think he means “the repository for querying”.
LikeLike
Reblogged this on Nguyen Van Tuan.
LikeLike
hey, I’m finally taking care of my blog again, and saw your comment but it seems your link is broken… 😦
LikeLike
Hi Herberto,
I consider your articles and the Dev Curricula one of the best resources about Software Architecture I have ever seen on the Internet. It had a big impact on my development as a software developer.
One thing is still hard to grasp for me. How would you divide your application into components when some part of domain is shared. For example you may have a domain model for Employee that is required both in accounting (sum up salaries for monthly balance) and human resources module (request a leave process). Should I place such part in the Shared Kernel or maybe a rule of thumb is to put two things into one component if they have anything in common on the domain level? Am I missing something?
Regards,
Wojtek
LikeLike
Hi!
Tkx, glad u liked it. 🙂
Regarding your question, it depends (cliché answer, I know 😬). There can be several reasons for that to be happening.
Most often what I see is that not the whole component needs to be shared, or just the data needs to be shared.
Using your example, I can imagine that Accounting doesn’t need the Employee name nor other data, just its ID, so I would put the Employee ID in the shared kernel and use the Employee ID in both components/bounded contexts (BC).
However, I can imagine that the HR module needs the Employee name, date of birth, etc., so I could do 2 things:
Keep 2 separated BCs, where the Employee BC contains the entities and services with the logic that changes the employee data, and in the HR BC uses query objects to get the raw data it needs (but not entities with business logic).
Merge Employee and HR modules in one BC, so that the HR logic can access the Employee entity(s) and business logic.
For me, it usually helps to ask myself “how would I do it if instead of a monolith I would have a micro-service ecosystem?”.
Hope this helped.
LikeLike
“in the HR BC uses query objects to get the raw data it needs” Do you mean using API to fetch the data from the Employee BC?
LikeLike
No, if it’s a monolith so we don’t need to use an API.
I see repositories as classes similar to collections, which return objects from persistence.
I see query objects as objects with a single method containing a (SQL) query which returns an array of data.
Entities are used to read and write data, but an array of data is only useful for reading purposes, ie showing data to the users.
An entity belongs only to one component, and only that component can instantiate it, and therefore tell it to do something that changes its data.
So if in component A we need data from component B, we can not a repository to get entities from B cozz they belong only to B, but we can use a query object belonging to A in order to get raw data that belongs to B.
This is more/less what we would do if we would have a microservice, with the difference that in a monolith we have only one DB while in microservices we have separate DBs with events coming in from other microservices to update the local data copies that belong to those microservices.
I hope I didn’t confuse you even more… 😀
LikeLike
I see. Thanks for your explanation. I’m trying to implement CQRS-ES within DDD approach on top of Symfony 4 here https://github.com/anhchienhoang/sf4-cqrs-es-demo. Please give some comments if you have time.
LikeLike
Hello, what software are you using to draw such as diagrams ?
LikeLike
Hi, i use Google Draw.
LikeLike
Thank you
LikeLike
I really love this articles. But need time to understand all. Is there any recommend books or course should i take for this?
LikeLiked by 1 person
Hi, tkx.
I don’t know about courses, I heard there are some teaching platforms like coursera, that have good online courses but I can’t say by my own experience.
But you can have a look to the list of articles, talks and books I’ve been compiling: https://herbertograca.com/dev-theory-articles-listing/
LikeLiked by 1 person
Hi I have question. What do you think about this approach:
Do you know why the default scope in Java is package-private? Because that’s what designers thought should be the most popular scope. Is that the scope you most often see? Probably not. Somehow Java devs became crazy communists-capitalists, recognising only private and public access, and preferring public everywhere. And so our projects look like a lawn right after snow melts: full of shit laying in public. Hard to put into your head. Hard to reason about. Entanglement instead of encapsulation. People even register every possible class in an IoC container, because FU (nctional) programming, that’s why. You wanna find something in my code? Google it. Or how about inheritance? James Gosling asked in 2001 about what he would do differently if he had a chance to recreate Java, said he would probably remove class inheritance. We are in 2016, having lambdas, defaults on interfaces, AOP and other tricks, but young developers still prefer to just add another abstract class to your code. Gonna be fun navigating those seven layers of hell when you read it. Ok, maybe it’s not THAT bad, but it’s not much better either. The problem, of course, is that we all start with tutorials, which cut corners for brevity. And we don’t pay attention to those small problems till they hit us hard. Let’s see how we can make our situation a little bit better, using Domain Driven Design, package-private scope, sensible packaging structure, and CQRS on microservices. Because it is actually easier than not doing it. Real life project examples included.
LikeLike
Hi, tkx for your comment!
Yes, I agree with you!
We have languages designed with privates, protected, publics, finals, abstracts… so that we can express intentionality in our code, so that our code is not used in the wrong way. We should use those artifacts a lot more than we do.
Maybe because of the nature of our industry where we have an ever growing number of developers, most developers are in the learning stage and most of us keep doing the same mistakes over and over…
Package level modifiers make total sense to me, for the same reason it makes sense to use class level modifiers. We should be able to clearly and objectively, without any ambiguity, define a package interface: the methods that other packages are supposed to use in order to interact with a package.
I don’t know how many languages have this feature, I just know JAVA does, although still limited, and PHP doesn’t. In PHP I end up organising the package structure with the classes that are supposed to be used outside the package in its root.
I also remember reading somewhere that JAVA might get improvements on its package level modifiers, but didn’t read anything about it recently…
LikeLike
Great article!! Do you have any link to a good code sample in C# implementing the architecture!! Thanks in advance!
LikeLiked by 1 person
Tkx!
Unfortunately not. However, I am currently working on a PHP implementation. I will write a post about it once I have it finished.
I hope sometime in this quarter, although I also need to dive into kubernetes…
LikeLike
Have a look at http://danielwhittaker.me. It’s all about CQRS ES and example code is in c#.
LikeLike
cool! Will take a look 🙂
tkx!
LikeLike
A simple example of clean architecture based on C# is found here:
https://fullstackmark.com/post/11/better-software-design-with-clean-architecture
LikeLike
Hi, you can check my github repository https://github.com/kgrzybek/sample-dotnet-core-cqrs-api. It is implemented in .NET Core 2.2. It is still in development but fundamentals are implemented (Clean Architecture, DDD, CQRS, validation).
LikeLike
Thank you very much for sharing your sample!! I will check it and share my thoughts!!!
Keep well and keep coding 🙂
LikeLike
How do you name Query(DTO) and Query(Handler)? xxxQueryDTO and xxxQueryHandler ?
LikeLike
Hi,
I would name it xxxQuery and xxxQueryHandler.
LikeLike
Hello,
Great post, I enjoyed reading all of your posts about software architecture.
I would like to hear your opinion on one topic – you have placed the event bus / message queue on the right side but I feel it we could be also added to the left.
Why? Actually the event bus / queue shares two responsibilities – from one side it’s the publisher / producer, and on the other side of the channel is the subscriber / consumer, and those responsibilities are normally handled by different applications / processes / bounded contexts. Consuming an event / message is just another way to trigger command in a distributed system. What do you think?
Aleq
LikeLike
Hi, tkx. 🙂
You have a very good point.
The way I see it, and as is in the infographic, the commands are on the left side because they start something, while the events are on the right side because they are triggered as a consequence of something that happened, they are driven.
However, I did put the command bus port/adapter on the right side and maybe it should be on the left side indeed.
Nevertheless, the event bus port/adapter I would still place it on the right side, as the message bus which is the underlying tool used by both the command bus and the event bus.
Either way it was convenient, for the infographic design, to have it in the right side although maybe I will change it now that u made me think about it. 🙂
Tkx for the feedback 🙂
LikeLike
I’ve been thinking more about this and I will not change it. Here’s why:
A primary adapter (on the left) adapts a use case to a delivery mechanism. This is the case with controllers, console commands and such.
A secondary adapter (on the right) adapts a tool to what the application needs it to be.
In the case of the command and event buses, they are adapters that wrap around a tool, the message bus, and adapts it to whatever interface the application uses.
Rationalizing it in this way, it becomes clear that really belong where they are located in the infographic.
Does it make sense to you? 🙂
LikeLike
Hi,
It makes sense, though I face more and more cases where I need to read messages from a queue (mainly background processes) and fire the same commands through Command bus as controllers do. But indeed it feels like queues are indirectly involved in “driving” a use case.
Thanks for your feedback.
LikeLike
Hello, I agree with @Aleq . In the case of incoming events to the application, the message queue is a delivery mechanism, it drives the application. The event arrives and it triggers a command on the left side in order to execute logic in the app that reacts to the event. A primary adapter would have to be created for taking the event from the queue and adapt it to a command.
In the case of outcoming events, events generated from the app, the queue is a tool on the right side.
Message queue plays both «roles»: for incoming events is at the left side, and for outgoing events is at the right side.
Regards,
Juan.
@hgraca … I would like to agree with you some day 🙂
Un saludo, Juan.
LikeLike
@Juan, fully agree with you
LikeLike
@Juan @Aleq I thought about it even more (thank you for the challenge) and here’s the cases I can forsee:
1.
The MessageBus (CommandBus & EventBus) is internal to the application.
So when we send a command or event we wrap it in an envelope saying what service (handler or listener) should receive the content of the message. As its internal, the application knows the message “language”, how to serialize and hydrate the message content and where and how to deliver it.
There is no need for driving adapters, only a driven adapter around the bus tool.
The MessageBus is external and we need to pull messages.
We need a driven adapter around the bus tool to pull messages. As these messages contents can (probably) not be hydrated, because they come from external systems, we will need something to translate these messages into commands. This “something” are the driver adapters, some controller like construct, for which there are already examples in the infographic. Nevertheless, the external MessageBus is still on the right side, as an external tool the application uses.
3.
The MessageBus is external and it pushes messages to our application.
In this case the message bus is totally independent of the application, so we don’t need a driven adapter. We do need driver adapters to translate the messages into commands, but that is basically an API endpoint which is an example that already exists in the infographic.
So, to conclude, I think that if we need a MessageBus adapter it will be in the right side, although it can forward message contents to adapters on the left side. Either way the infographic already has examples that can fit these cases.
I feel tempted to add these specific examples but I’m afraid it would overload the already overloaded infographic. 😦
Hope this is clear and we can finally agree on it. ☺
Again, tkx for the feedback and making me think about these things.
LikeLike
Hello @hgraca… as always, it’s all in the language… «We do need driver adapters to translate the messages into commands, but that is basically an API endpoint»… we talk about the same thing but name it differently and we put it at the left side in each one’s architecture. So name it whatever you want, but we are talking about the same concepts. We have different terms, different architecture (but very slightly), different ULs, different «contexts» when we talk… but in the end we are saying the same thing.
Regards, Juan
LikeLike
Hey mate,
Quick question: Where would you put your Command Validators (using a Command Bus and a Validation Command Handler decorator); in the Port or in the component itself?
Best..
Fadil
LikeLike
One more thing: I used to use Fluent Validation for validation. In this kind of architecture, would it be still possible to use the library and where you it be used? I don’t think it should be in the component since it should be technology-agnostic. Any thoughts on that too?
LikeLike
I would create a validation port/adapter, so that we could switch the validator lib for another one or for a new BC breaking version, and would inject that port/adapter into the command bus validation decorator or middleware.
LikeLike
Hi
It depends on how you implement it:
1. If that decorator is something simple, specific to a command/handler and what actually knows the rules to validate the command data, I would put it in the component as it will be used only by that component.
2. If it is something generic that can be used in any command/handler and gets the validation rules from somewhere else (ie. yaml or annotations config), then I would put it in the command bus port/adapter as it can/will be used by any component.
LikeLike
Herberto,
Thanks for writing this piece. I think it’s all coming together for me now.
Do you have any thoughts on how to model or apply DDD and best practices on rich front-end apps like SPA or Android / iOS apps?
Thanks,
Melvin
LikeLike
Your welcome 🙂
I don’t have first hand experience with front-end apps. I’ve only been doing back-end. However, I can imagine it is perfectly possible to follow these ideas, although maybe with some differences derived from technology differences/limitations. For example Phyton doesn’t have interfaces, and that will certainly bring differences in implementation. I imagine the same will happen with other technologies. 🙂
LikeLike
Hi Herberto.
I just wanted to say thank you so much for the Software Architecture Chronicles and in particular this article.
I’d been developing websites (Joomla primarly) for the past few years however recently I’ve started learning more about enterprise architecture patterns for C# application development. Over the past few months I’ve read countless books and articles and watched numerous videos all explaining aspects of and approaches to domain driven design, CQRS, Ports and Adaptors, Mediator, etc. Whilst each has added to my knowledge of the various topics I can honestly say that no other source managed to put it all together as clearly and succinctly as this article. This article brought it all into focus for me. Thank you!
Cheers,
James
LikeLike
I think I now understand what you meant. Thanks a lot mate!
LikeLike
I was gonna reply later, but im glad u already understood. 🙂
Cheers!
LikeLike
Makes sense yes. Thank you.
Where would put your Query Objects though? Application layer?
LikeLike
Yes. Domain objects don’t care where other domain objects come from, and know nothing of persistence.
Tha application layer is the one that needs to know to what entities a use case applies to, so it needs repositories and query objects.
LikeLike
Hmm, okay.
In your previous reply, when you said:
“Ideally this interfaces would have only one method, which would spit out a DTO (belonging in the persistence port) that would be expected_by/specific_to each persistence adapter.”
Why would you create DTOs when you can use the Query Objects themselves in the persistence port and adapter? And where would you please those DTOs?
LikeLike
Great post!
I have two questions regarding Persistence.
Imagine you have one Persistence port which abstract an ORM (let’s say Dapper) and your application is using that port for persistence to the relational database using Stored Procedures. So you would normally implement that port with methods such as Execute(string query, object parameters) and Query(string query, object parameters).
Question 1: Now let’s say you need to change your persistence engine to using NoSQL databases for instance. Normally you would need to write a new adapter for your NoSQL database. But would that means you also need to change your Persistence port to use NoSQL-related methods such as Save(object item), Delete(long id), Get(long id) and Update(long id, object item)?
Question 2: Since your application core (application and domain) depends on your Persistence port, would that not couple the domain with “relational” persistence concepts?
Thanks!
Fadil
LikeLike
Perhaps, creating two ports/interfaces, one RelationalPersistenceService and NonRelationalPersistenceService?
LikeLike
Thank you.
I see the repositories and/or query objects as adapters over a query language as opposed to adapters over a tool.
Furthermore I think an application will always be dependent of languages (sql, dql, mongoql, the same as depending of PHP, java, whatever).
The persistence adapter will adapt over Doctrine or whatever ORM we use.
I think that if we use a command pattern (no relation to command bus), we can leverage a clean persistence port. The idea would be to create a Query Object as a DTO, which is passed to the persistence port. Whatever adapter receives it will know how to translate that DTO (the query object) into what the underlying tool expects. This means that the adapter would only need to implement one method ie “handleQuery”.
Furthermore, the port could be composed by an interface AND a strategy pattern implementation, which would have whatever adapters inside and when receiving the query object would decide what adapter would be used. So if it would receive a SQL Query Object it would deliver it to a PDO adapter, if its a MongoQL Query object delivers it to the mongo Adapter, and so forth so on. This way we allways inject that Proxy/strategy implementation and dont care about injecting the matching adapter to the query object we use in the client code.
Did it make sense? 🙂
LikeLike
Thanks for the explanation.
Let me give you some context on what I need to achieve.
I am using ORM (Dapper) which calls stored procedures. I have a Transaction Repository which uses the persistence port. The persistence adapter then wraps around the ORM to execute/handle queries. But because I am using stored procedures, the client code (Transaction Repository) will need to pass the SQL parameters and specify which stored procedure to use (the persistence adapter by itself does not know which stored procedure to use).
Now let’s say tomorrow I need to use MongoDB instead of SQL Server, the client code does not need to specify which stored procedure to use anymore. The client code will need to specify the collection name and the object to persist (again the persistence adapter by itself does not know about which collection name to use).
Then let’s say I need to use Elasticsearch instead of MongoDB, the client code does not need to specify which collection name to use anymore. The client code will need to specify the index name and the object to persist (again the persistence adapter by itself does not know about which index name to use).
So in this case, does that mean you need to explicitly model your Query Objects with persistence-specific concepts such as:
public interface IRelationalQueryObject
{
string QueryName { get; } // which contains the name of the stored procedure to call
object Parameters { get; }
}
public GetAllTransactions : IRelationalQueryObject
{
string QueryName
{
return “[dbo].[GetAllTransactions] @DateFrom, @DateTo”;
}
// …
}
OR
public interface INoSqlQueryObject
{
string CollectionName { get; } // which contains the name of the collection to use
object Data { get; }
}
public GetAllTransactions : INoSqlQueryObject
{
string CollectionName
{
return “Transactions”;
}
// …
}
OR
public interface IIndexQueryObject
{
string IndexName { get; } // which contains the name of the index to use
object Data { get; }
}
public GetAllTransactions : IIndexQueryObject
{
string IndexName
{
return “Transactions”;
}
// …
}
What I am trying to say is that the client code (Transaction Repository) somehow needs to know the “type” of Query Object beforehand in order for the strategy implementation to know which persistence adapter to use.
Thanks..
Fadil
LikeLike
Well, I see Query objects and Repositories as adapters around a query language, and I see it as ok for the application core to know what language it wants to use, although I agree that ideally it wouldn’t care. So it depends on how far you want/need to go with it.
If you really want to abstract from the query language, you can have a QueryObject that is initialized with the data filters, and it can implement different interfaces (belonging to the persistence port) where each interface corresponds to one query language. That would make it possible for the same query object to be used with different persistence mechanisms, so the client code would be agnostic to the query language (which would only exist inside the query object) and to the persistence mechanism (which would be behind the persistence port).
Ideally this interfaces would have only one method, which would spit out a DTO (belonging in the persistence port) that would be expected_by/specific_to each persistence adapter.
When the persistence port (through a proxy/strategy object) would receive a query object would check what interface it implements and would forward it to the corresponding adapter (mongo, PDO, Doctrine, Elasticsearch, …). However, if a query object implements multiple interfaces, this means the persistence port (proxy/strategy object) would need to have a smarter mechanism to choose which persistence adapter to use, maybe using a priority list set in the configuration.
Does this make sense to you? 🙂
LikeLike
Hi,
I agree that entities should never use a repository, but not entirely sure about its use in Doman Services, f.e. when applying business rules regarding some type of data validation (stored in database) before a command execution.
However, if you place repository in Application layer, the use of repositories is restricted in Domain, but they could be used from Presentation, as it can access to all Application functionality. And in a DDD context, I don’t think this is really correct, as any access from UI should be through Application Services or Command/Queries Handlers.
Anyway, I don’t agree with @Juan about that infrastructure depends on both application layer and domain model in DDD. From my point of view, dependencies in DDD do in this way:
Application –> Domain <– Infrastructure
Where domain is the core of everything.
It’ll be interesting to know your opinions about all the things discussed here.
Regards.
LikeLike
Hi @jantonioreyes. Infraestructure must depend on Application Layer in order to implement the application logic that needs to deal with technology or frameworks.
For example, transactions are a cross-cutting concern that should live in the application layer, and the implementation (with Spring framework for example) should live in the infraestrucure.
Sending a notification is another example of application logic. The interface lives in the application layer and the implementation (using email, sms or whatever) lives in the infraestructure.
Look at the layered architecture diagram using DIP (page 124 in the book “Implementing DDD” by Vaughn Vernon). Infraestructure depends on all layers.
I don’t use layered architecture though. I use hexagonal architecture, but it’s similar: application logic belongs to the inside of the hexagon, and it can use ports (interfaces that belongs to the hexagon too). This ports are implemeted by adapters (the infraestructure, the outside of the hexagon).
Regards, Juan.
LikeLike
I dont agree with you on this. I think dependencies go like this:
Delivery Mechanism (http, console, …) <- UI -> Application –> Domain <- Application – > Port <- Adapter – > Tools (ORM, SearchEngine, Emailing , …)
LikeLike
Where do you implement application logic that needs infraestructure? For example, security (identity and access management), transactions, logging, etc. It’s not domain logic.
Un saludo.
LikeLike
Sorry, half what I wrote disapeard !! 😀
I think dependencies go like this:
Delivery Mechanism (http, console, …) <- UI -> Application –> Domain <- Application – > Port <- Adapter – > Tools (ORM, SearchEngine, Emailing , …)
LikeLike
Finally, I managed to fix my comment!!
The security (identity and access management), transactions, logging, all that is infrastructure, its not Domain logic nor Application logic.
Although logging is a special case, as it is cross cutting…
LikeLike
I agree. Application uses ports. And ports are implemented by adapters (infraestructure). I do it that way too.
LikeLiked by 1 person
Hi Herberto, this is a nightmare hahahaha. I saw your fixes now. Well I agree about dependencies (more or less, although my architecture is slightly different, but the essence is similar). I don’t agree about this sentence though:
“The security (identity and access management), transactions, logging, all that is infrastructure, its not Domain logic nor Application logic. Although logging is a special case, as it is cross cutting…”
Security, transactions, exception management, and more, are cross-cutting concerns too and they are centralized in the application layer. For example, if you use the command/query bus (I do), they are command/query decorators in the application layer.
Our arguments are a never ending story 🙂 We have different points of view here, you consider yours is correct, I consider mine 🙂
Maybe we should stop aguing about this… it’s for sure that maybe we will find other topics of discussion 🙂
I like to talk about these thinkgs though, and share knowledge, undertanding and points of view. I appreciate your posts, as I like DDD and ports&adapters architecture.
Regards,
Juan.
LikeLike
Yes, we could discuss this stuff for a long time… 😂
But its a interesting discussion.
I wonder what we would come up with if we would ever work together 🙂
LikeLike
Hahaha. Well I think it would be a good team after all. In the end I think that sometimes
we are saying the same thing… I also could say that security, for example, is an infraestructure service in the sense that implementation lives in the infraestructure layer (adapter). But sometimes clearly we say different things (I say that security is crosscutting concern).
Again, congratulations for your great posts. I think I’ve found more topics for discussion :), but I will tell you another day when I have time 🙂 this is a hobby for me, as in my job DDD and hexagonal architecture are not used. I use them in a personal training project, to put in practice all my lesrning about these subjects. I hope that some day I could publish all my learning and knowledge like you do. But time goes by and it’s not enough for me.
Un saludo Herberto… keep it going
LikeLiked by 1 person
And as for the Domain services, I still don’t see a reason for them to know about persistence.
They perform some domain logic on domain objects. The domain object should be passed to them and they do the logic, they don’t care where the domain objects come from.
🙂
LikeLike
Hi Herberto… I’m back 🙂
in reply of:
“The security (identity and access management), transactions, logging, all that is infrastructure, its not Domain logic nor Application logic.”
Security and transactional management are application logic (they belong to application layer). When I say this I mean that at least interfaces of transactional and security live in the application layer. But as any other services, if their implementation need technology, the implementation should live in the infraestructure layer.
Look at page 120 of The Red Book:
“Application Services reside in the Application Layer. … They may control persistence transactions and security.”
And page 521:
“… the Application Services also control transactions … Security is also commonly cared for by Application Services.”
And page 533:
“… infrastructure … works out very well if its components depend on the interfaces from … Application Services … that require special technical capabilities.”
And page 113 of the book “PPP of DDD” by Scott Millet:
“Application services contain application logic only. This logic covers security, transaction management…”
Un saludo,
Juan.
LikeLike
Well, i have to admit that in a small/medium application thats how it will work indeed. However, in an enterprise application we will most likely use a command bus and the transaction start/end/rollback will be controlled there in a middleware. But yeah, i have to agree that application services may control persistence transactions. 🙂
When it comes to security, i can agree that in some cases it might be desirable, but in most cases i want to control who can access a view and that i do in the controller, usually through configuration of an infrastructure service, like the doctrine security annotations. So no application layer involved. 🙂
LikeLike
Hola Herberto…
“Well, i have to admit that in a small/medium application thats how it will work indeed. However, in an enterprise application we will most likely use a command bus and the transaction start/end/rollback will be controlled there in a middleware.”
In that case (enterprise app with a command/query bus), an easy way to control all those application concerns (transactions, security, logging, etc) is with decorators that wrap the commands/querys. The bus is the entry point to the app, and decorators are wrappers around it. In this case command/querys, their handlers, and the decorators, all belong to the “application layer”.
“When it comes to security, i can agree that in some cases it might be desirable, but in most cases i want to control who can access a view and that i do in the controller, usually through configuration of an infrastructure service, like the doctrine security annotations. So no application layer involved.”
Of course. Views and controllers are out of the hexagon, they dont belong to the core app. They are the UI.
Un saludo,
Juan.
PD: sorry I quote your words in order to response, because your comment doesn’t show a “reply” link.
LikeLike
Solved the “reply” limit, it was set to 3, now its 10 (the maximum). I didn’t realise this problem existed, so tkx for letting me know.
Back to the subject, the application layer is all about the use cases. In order to perform the use cases we need to get entities out of the persistence, and we use a persistence port to get those entities and to persist them back.
But that is all the use case needs from the persistence mechanism, get and put entities from/in persistence. If it uses transactions or not, it’s not a concern of the use case, it is an implementation detail. If we put transaction control (begin, end, rollback) in a use case, then if we switch the persistence tool to something that does not use transactions, does it make sense to leave those method calls in the use case? I don’t think so.
That being said, if its a small application I wouldn’t care about it and would just put it there.
If its a medium size application I would try to bind the transaction control to request/response events. For example Symfony has events when receiving a request, when sending a response and when there is an error, so I would those events to the transaction start/end/rollback.
If its a big enterprise application, then I would use a command bus and take care of transaction control in a middleware in the command bus.
Where would that middleware live?
Well, it is not specific to any component, so it will be use by all components, so it will be outside the components application layer.
Maybe in the persistence port or in the command bus port (ports are also application layer)? In this case that would mean that the middleware would be exactly the same for any persistence and/or command bus implementation which would be very hard, if not impossible to achieve.
The remaining option is to put it in an adapter, which is outside the application layer. And this is in line with the fact that transactions are an implementation detail of a persistence mechanism, not relevant to a use case logic.
Does this make sense to you? 🙂
LikeLike
Well, I think that maybe 10 replies is not enough for us :).
Transactions has to do with application services (or command/query handlers), as every use case has to be executed inside a transaction. Use cases are transactional.
But I’m not saying that a use case calls the methods to control transactions (begin, end, commit, rollback). I put transactional mechanism as a wrapper (decorator) of the application service interface (or command/query bus). This wrapper lives in the application layer, and it calls a port (implemented by an adapter that lives in infraestructure).
If, as you said, we switch the persistence tool to something that does’t use transactions, I switch the transactional adapter to another one that does nothing, or simply I don’t apply the wrapper to the application services.
In the end, I think we are saying more or less the same things. Maybe it’s my fault that I don’t express myself well in english. Maybe we don’t speak the same UL and I have to put an ACL, because it’s for sure that you are the upstream side 🙂
The issue in which we don’t agree is where the code that apply transactional concern to the use cases (being these services or command/query handlers) should live. For me, this code should live in the application layer because it is application logic, based in what I have read about the subject (I put here some references to some books pages). But this code is not implemented in the application layer, because the implementation is technology dependant. So this code use a port that is implemented by an adapter (infraestructure). I name this port “transactional port”.
I think that I’m not going to convince you and you are not going to convince me neither 🙂
Regards,
Juan.
LikeLike
Haha!
Yeah, lets agree on disagreeing! 😃
Lets go for a beer if u ever come to Amsterdam 🙂
LikeLike
Hahaha, I guess we would get drunk while arguing, because we will never agree 🙂
But maybe not, maybe speaking face to face we would realize that we are saying the same thing. It’s all about language. Spoken language better than written. Speaking to each other makes a shared understanding . Like Jeff Patton says in his book about user story mapping technic, speaking with the user is better than written user requirements documentation.
By the way do I have your permission to put a link to your posts if I write mine about all these subjects? I don’t know if I will but it’s my intention to publish all the knowledge I have learnt about putting together ports&adapters, DDD, etc, and to publish source code as well.
Though we don’t agree in some things, I think that your articles are great and that you have done an amazing work.
Saludos,
Juan.
LikeLike
Sure, go ahead.
Im also preparing some code for my next post, but its taking me a long time…
LikeLike
Yes, I understand you. It takes a lot of time. Me too. I don’t have enough time to do all that I want.
Keep it going.
Bye.
LikeLike
Hi Herberto, I just ran into a case along the lines of what you mention here.
I have some data retrieved via the repo (a collection of max. 5 elements: line items in an order) and I must further process the collection according to some context-specific business rules to determine which of the various line item is relevant for my specific use case.
The filtering logic is clearly a Domain service responsibility (SpecialCaseLineItemService), but I was thinking of what you said: “I still don’t see a reason for them to know about persistence”.
My questions:
1. I will apply the same filtering logic in three specific places: RetrieveCase1(), RetrieveCase2() and SaveCase() – will it not make more sense to wrap the repo inside the domain service?
2. Do I inject the domain service into the application service?
Thank you.
LikeLiked by 1 person
Hi,
Well, if we fully control the collection object, I would put the filtering logic in the collection object, so the collection (which is a domain object) would have several filtering methods, which could be used in application services.
If we don’t control the collection (maybe because the ORM spits out one of its generic collections), then I would probably use a collection wrapper which would contain those methods (it would be something like a Domain service) and use that one in the application services to wrap the collection and then filter it.
So:
1. I wouldn’t do it this way because then the domain service (domain layer) will have knowledge about the repository (application layer) so it would break the dependencies rule.
2. Indeed, I would prefer to use the repository in an application service, use the repository (application layer) to get all of the line items as a collection (domain layer), and filter it using the collection methods.
Does this make sense to you? 🙂
LikeLike
I am new to DDD world and am rethinking a bunch of old problems in a new light.
Your answers make a lot of sense, in fact you just made me rethink that part of the model concerning the collection of objects: it is a class in itself, representing a business concept.
P.S. Thanks for replying so quickly, appreciate it. Have a nice day!
LikeLike
Your welcome 🙂
LikeLike
Great article.
Thanks for this post.
I’ve a doubt about just one point, where you’re talking about put repository interfaces in the Application Layer. According to DDD we use to put them in Domain, so if they belong to Application, where they must be implemented?
If interfaces are in Application, and implementations in Infrastructure, must Infrastructure have dependencies from Domain and Application layers?
Thank you so much, and keep it going!
Regards.
LikeLike
Hi, tkx for your comment.
I put both the repository interface and the implementation(s) in the application layer.
I see the repository interfaces as an abstraction over a query language. So there can be different implementations of the same repository interface, each implementation using a different query language, ie one implementation with DQL, another with SQL, another with Mongo QL, …
Each implementation gets injected a persistence interface which lives and is implemented in the infrastructure layer. The persistence interface implementation injected can be different for all different repositories or it can be the same by using a strategy pattern.
I hope this was clear…
In my next post i have an example of this implementation. 🙂
LikeLike
Hi hgraca, I don’t agree with you at this point. I think that neither putting repo interfaces nor their implementations in the application layer is right from a DDD point of view.
Repo interfaces belong to the domain, one Repo per Aggregate Root. And the implementation should live in the infraestructure layer, implementing the repo methods (named using the UL) with languages according to the storage (SQL, Mogo, etc).
The application layer, as the direct client of the domain, uses the repositories interfaces.
Persistence is not a cross-cutting concern, like transactions, logging, exception handling, etc, so persistence shouldn’t live in the application layer.
Well that’s my point of view from what I’ve been learning about DDD. Maybe I’m wrong.
In response to jantonioreyes, I wanted to say that in DDD, infraestructure depends on both application layer and domain model. In order to implement cross-cutting concerns, the interface lives in the application layer and the implementation lives in the infraestructure.
Regards, Juan.
LikeLike
That’s fair enough 🙂
However, if you place repository interfaces in the domain layer, that means that an Entity could eventually use a repository. I think that should never be the case. So by putting the repository interface in the application layer, you explicitly say that a domain object should never use a repository.
Collections, on the other hand, yes. We can have a User and a Role entities in a 1-* relation, and then the User will contain a collection of Roles, and that collection can contain business rules inside.
I have never encountered a case where a domain object (entity, value obj, collection, specification, …) would need to know about persistence.
A use case, on the other hand, needs to know to what entities it applies to, needs to get them from persistence, tell them to do something, and persist them again.
Furthermore, I don’t think the repository implementation should live in the infrastructure because a repository is specific to a component, it should not be used in other components. A repository is not cross cutting through components, unlike the persistence interface which will be used by all components.
This is how I see it anyway 🙂
LikeLike
Hi again,
Just a pending doubt about my previous question, now that I’m trying to implement an hexagonal architecture.
If repositories interfaces and/or implementations are located at Application layer, as @hgraca proposes, and not in Domain (interfaces) and Infrastructure (implementation) f.e., then it should be possible to access to repositories directly from Presentation. I think this make possible to skip all the logic implemented in the use cases, despite this could make direct queries faster, or it could be also used at a Presenter handler.
What do you think about that?
Regards and thanks in advance.
LikeLike
I think either way the Presentation layer can access the repositories because it’s the outermost layer and therefore can access any of the inner layers.
You can decide to make the layers access only the layer next to it, but that might end up creating a lot of indirection layers in the code. The so-called lazagna architecture. 🙂
My main points about repositories in the application layer are because the entry/exit points in the application are located in the application layer, and it would be awkward for an entity to be allowed to use a repository.
LikeLike
Thank you,
I was thinking about this matter. The question that I don’t like repositories in the application layer is that, for me, repositories return Domain entities, so I don’t like these entities to be exposed outside the application layer.
So, dealing with Clean architecture, I have decided to declare repositories in Domain to manage entities on the one hand, as I use to do with DDD. And on the other hand, I will define Query interfaces in the Application layer, more or less like Read-only repositories but trying to optimize the implementation as much as possible and returning Use-cases response objects directly. Both, repositories and queries, implemented in Infrastructure.
What do you think about this approach?
LikeLike
I think that is a very good approach.
Using query objects, that return raw data in an array or DTO, is also my prefered way to expose data to the UI, while I prefer to use repositories only in the use cases themselves because they return the entities with the domain logic the use case needs to trigger.
LikeLiked by 1 person
Thanks for your answer, I appreciate it a lot too, because the architecture of my project is very similar to yours, I’m a fan of ports and adapters architecture and DDD. When I saw this post I said: “this is amazing, perfect”. And the picture of the whole architecture is awesome. In general, your posts are great. I say it because it’s what I really think.
By secondary ports I mean what you call just ports. They belong to the core but I split them phisically apart (core = domain model + secondary ports). Domain model depends on secondary ports. They are interfaces for talking to external actors (systems,humans,services,databases or whatever). The language of the port methods signatures are the language of the core. A secondary adapter implements (depends on) the secondary port for a specific external actor and technology. I said Repository (persistence port) as an example of secondary port. In my case I split the core in modules (DDD concept), more or less is what you call component. A module has one or more aggregates, each one with its repository interface. This aggregates repo interfaces should be the secondary port, but if I place them (one per aggregate) in the port, then I break the “package by feature” design. So I decided to add kind of a “port proxy” in the domain model, that gets the port injected and forward the method calls to the port. By this I add complexity and duplication. But if I don’t do it, then the persistence adapter (repo implementation) should depend on the whole domain model, and that’s not correct from my point of view. Every secondary adapter must depend just on the secondary port that it implements.
I think your answer (“Repositories are specific to a component, si I place them in its specific component. They depend on the ORM port, it is injected in the repository constructor”) is more or less what I mean.
Thank you very much.
PD: Just one more question: do you have a persistence model in the persistence port, different from the domain model, and a translator between the two? Components of the domain model depend on persistence port and persistence adapter depends on the port too. Port doesn’t depend on anything, so it knows nothing about the domain model.
LikeLike
Thank you again for your comment, quite interesting how you do see it, and how similarly we do it! 🙂
I’m not quite sure what you mean by a persistence model. However, I can say that the persistence port indeed knows nothing of the domain although all ports should be designed to fit what the domain needs as opposed to what would be easier to implement by the adapter. Otherwise, the adapter is just a wrapper around the tool. In other words, we should first design the port as it would be easier to use by the components, and then implement the adapter.
In my concrete case, I use Doctrine (similar to Hibernate) which is an ORM that uses a data-mapper pattern, as opposed to an active-record pattern, so I can indeed have a data model completely different from the domain model, although that is not usually the case, and the mapping from domain model to data model is set up with configuration files understood by the ORM itself.
Did this answer your question? 🙂
LikeLike
I totally agree with you.
By persistence model I mean the model mapped to the database. I use jpa and xml mapping, in order to not polute the entities with annotations. Again, I think it is similar to yours.
Of course you did answer my question.
Thanks again.
I’m looking forward to see your next articles.
Regards, Juan.
LikeLike
Hello. Great post. Congratulations.
How do you deal with secondary ports and components?
Do you consider a port being part of the component, or is the port a separate layer?
For example, if each component owns its repository the secondary adapter should depends on all components (the whole app core, not just the ports).
But if you put ports in a separate layer, the you break package by component design.
Thanks, Juan.
LikeLike
Tkx for your nice words, I appreciate it. ☺
As for your question, I don’t understand what you mean by ‘secondary ports and components’. But maybe this will make it clear:
If my application uses an ORM, I will create a Persistence port and an adapter for the ORM. That port will be used by all components that need the ORM. The ports belong to the application core, its an entry/exit point to the application core, not to a specific component.
Repositories are specific to a component, si I place them in its specific component. They depend on the ORM port, it is injected in the repository constructor.
The tricky thing with repositories is that they are also specific to the query language. They implement a repository interface, but then there can be different implementations per query language. A query language depends on the persistence engine used, it can be SQL, Mongo Query Language, Elasticsearch query language, Doctrine Query Language, … whatever.
This means that a repository, although not an adapter around the ORM, it is an adapter for the query language, and it might need to know some specifics about what is outside the Application Core, it definitely needs to know what language it is using, and if using DQL it needs the doctrine query builder to be injected. Unless we create our own query language, like Doctrine did, but I think that is going way too far.
Did this answer your question?
LikeLike
Hello. Why do you think that put ports in a separate layer, the you break package by component design? Your packages/modules may strictly require other module which in this case may be it’s bounadry. Uncle Bob described it like “plug-in approach”. So consider next packages relation structure:
+——————- +———————+ +—————+
| Infrastructure | | UseCase | | App impl |
| module where |==requires==>| boundary |<==requires==| where |
| ControllerA | | where is | | ConcreteA |
| belongs to | | < I > ContractA | | belongs to |
+——————-+ +———————+ +—————+
Infrastructure do knows about boundary and only about it as a contract but dependencies are still inwards. So ControllerA –depends on–|> ContractA implemented by ConcreteA. What is breaking this way? Packages may require other packages to be a part of it so it’s still top level package by component. And packages may be re-used at other packages/components so it’s way like plugin. As for example – to publish an IDE plugin you don’t have to publish whole IDE with it.
LikeLike
Hi, I explain it in my reply to hgraca ( https://herbertograca.com/2017/11/16/explicit-architecture-01-ddd-hexagonal-onion-clean-cqrs-how-i-put-it-all-together/#comment-753 ). In my implementation of hexagonal architecture, I have a jar for every port and another jar for the core (hexagon = core + ports). Ports are the boundary of the hexagon. The outside world (adapters) access the inside through ports. I have a jar for every adapter. Core depends on ports (interfaces), and every adapter depends on the port that it implements. Ports isolate the core from the outside. So say you have ComponentA and ComponentB in the core. RepositoryA and RepositoryB are interfaces belonging to the persistence port for accessing the database, so they both belong to the “persistence port”. But this breaks “package by feature” (because RepositoryA should belong to ComponentA, and RepositoryB to ComponentB). My solution was to add a RepositoryA class in ComponentA, that just gets injected the RepositoryA interface of the port, and forwards every method call to the port. Same for B.
Apologize to hgraca, this is your blog, not mine (I don’t have any), but I’ve answered as the question was about something I said.
Regards,
Juan.
LikeLike
No need to apologize Juan, the more ppl participate the better.
One of the reasons i created the blog was to give back to the community, and we are all part of it 🙂
LikeLike
I am amazed by this post. Great work 🙂
LikeLike
Thanks for this article. Very detailed.
LikeLike
Reblogged this on Pikachu's Corner.
LikeLike
Thanks for the article.
Great subject.
Would you be willing to present that at Wajug user group (in belgium)?
We’re looking for great speakers and great subjects.
Have a look at our upcoming/past events:
http://www.wajug.be/
http://www.wajug.be/pastEvents
Hope to hear from you,
Stephane
LikeLike
Thank you!
I feel flattered now!! 🙂
Liege is a bit out of my way though…
But I still wanna write a few more posts and then if I decide to make some talks I will send you guys an email.
Thank you for the invite, I really appreciate it.
LikeLike
You’re welcome, I really liked your post.
No problem, contact me when you’re ready for some talks.
It will be a pleasure to host you.
And Liege is not that far from Amsterdam 😉
In the meantime, good continuation with your excellent articles.
Cheers,
Stephane
LikeLike
First I would like to say that this is a very good summary of all the concepts (DDD, CQRS, P&A etc…) into one coherent whole solution and also to take the opportunity and say that I really enjoy reading your blog posts.
I’m familiar with the ideas mentioned in the post for several years now and also I’ve been following those topics in various places: blogs, books, conferences and more and also tested\implemented some of them myself in various projects to some extent.
There 2 main issues that bother me the most regarding this and I’ll be very happy to hear your opinion.
1) Creating many abstraction and separations (Domain objects, Domain services, App services, DTO’s , Persistence adapters etc.. ) is adding a lot of entities to maintain and also many mappers between them – this creates A lot of boilerplate code that is hard to maintain. For example I have at the minimum 3 flavors of the same entity – one for the primary adapters (i.e. return User to the UI\service-client), second for the domain, third for the persistence adapter. (Usually it’s simple 1:1 mapping but obviously not always)
2) Such abstractions creates significant performance penalty mainly on data driven applications. For example let’s look on the separation between domain and persistence. We aspire to keep the business code isolated inside the domain and treating the persistence as storage mechanism – we can save or getBy (filter) but we try to keep the business decision\logic inside the domain – doing so can lead to a very inefficient usage of the persistence (I.e. DB) – for example instead of creating a more complex query that will do some of the calculation on the DB itself we fetch a lot of data, translate it to domain, perform the calculation and return the result. The question is how you prevent leakage of business rules into the persistence adapter while still keeping the process efficient as possible.
LikeLike
Hi,
Thank you, I’m glad you have been enjoying my posts. 🙂
Regarding your questions:
1) Yes, you are absolutely right. Doing all this creates more code.
However, I don’t think it has high maintainability costs as once it is done, it just sits there. If we need to change it, it’s better to change in that one place, as opposed to everywhere where the actual tool would be explicitly used. But on the other hand, it does give us the advantage of easily changing how we handle the actual tool behind the port/adapter.
For example, at my current company we had an adapter for the symfony event dispatcher and all our core only knew about the interface in front of the adapter. When we decided to start using async events, we just had to create the adapter for the async events and add it to the list of adapters being used by the actual dispatcher being used in our application.
The same thing goes for the cases where we want to upgrade some library version. If we have an adapter, we just need to write a new adapter, the application core will stay the same.
These practices give a lot of stability to the application core.
Nevertheless, Software Architecture is all about tradeoffs. So, if the project at hand is not going to be long-lived, or the company is still in a stage of lean-startup, and creating these ports/adapters will be too time-consuming, maybe it’s better to just use the tools directly throughout the codebase. Also keep in mind that there are ports/adapters easier to create than others, so maybe we can create the ones that are easier to create and not the most difficult ones.
In the end, it’s all about tradeoffs. The important is that we know all these patterns, because they can help us at some point, but we use only what is worth using in a specific context.
2) Picking up your example “for example instead of creating a more complex query that will do some of the calculation on the DB itself we fetch a lot of data, translate it to domain, perform the calculation and return the result. The question is how you prevent leakage of business rules into the persistence adapter while still keeping the process efficient as possible.”
I think that the actual domain is the fact that we use the result of that specific calculation, not the way we actually calculate it. So, I would create a query object with a class name and method name that accurately reflects the calculation being made from the domain point of view, and have the DB make that calculation for me and just return the result. Since we only want to get data, we dont need to use an ORM to hydrate the data into entities. We only need to hydrate entities if we want them to “do” something, as opposed to just give use some data to show our users.
I use query objects when I just want to get data. A query object only has one query inside.
I use repositories pretty much as collections. A repository always returns an entity or set of entities.
I hope this helps.
LikeLike
Thank you for your great post/article. Wish to have it couple years earlier. Everything described amazing but still have one question: at previous comment you told about that when you do a Query and you only need the data you do it avoiding ORM and other stuff. That is a way that I usually do. For instance I have a controller that depends on, lets say LastMonthDeposits – contract of a query, which is implemented by LastMonthDepositsPostgreSQL which depends DIRECTLY on connection. And at schema your query depends on contract of persistence which is implemented by persistence adapter which depends on whole ORM and so on. So why would anyone choose to go all the way down through ORM instead of be specific? And in terms of PHP – why would anyone use adapter over doctrine/orm instead of direct doctrine/dbal (query level cache is it’s responsibility) in case of Query, not Command handling?
Yes, I have read that it’s just a guideline and so on but the main thing that I’d like to know is what were the preconditions/circumstances to emit such particular guideline?
LikeLike
Hi, tkx.
If I understand correctly, your question is “Why does the query object implementation depend on the persistence port, whose implementation uses the ORM/DBAL, instead of the connection directly?”
There are 2 things I wanna point out to answer your question:
1.
The reason is the same as usual, by making the query object implementation depend on the port, we can change or completely swap the persistence implementation without changing the query object implementation (as long as the query language is the same). For example, if we use a port/adapter we can add a line of code to the adapter to log all queries being made. In the other hand, if we inject the connection in all our query objects, to add the same logging we will have to add that line of code to all the query objects and inject that logger into all of those objects.
2.
The implementation of the persistence port does not need to be the same. So, for commands, you can use an implementation (adapter) that wraps around the ORM but, for the query objects, you can use an implementation that wraps around the DBAL, or the connection itself. This way, you can skip the ORM and/or DBAL overhead when you don’t need it and still have the flexibility that the port/adapter brings us.
Did this answer your question?
LikeLike
Hi, may I ask about final infographic in scalable version (vector pdf or svg) to printout on the wall in my developers office ? It’s very good and I think I may be usefull many times. Thank you
LikeLike
Sure, here you go: https://drive.google.com/open?id=1E_hx5B4czRVFVhGJbrbPDlb_JFxJC8fYB86OMzZuAhg
LikeLiked by 1 person
Wow, that is an article! Thanks for putting such a huge amount of work to compose it.
I have a lot of questions about proper architecture but the most struggling one which is bothering me in my work is authorization.
Would you mind to put some light on how you’d design authorization across all the layers and components? You mentioned that component itself can be of the purpose of authorization. How does it all work together?
LikeLike
Tkx. 🙂
I would use an ACL module. I would try to find an ACL module, a tool, that I could just create an adapter for it and protect the routes according to what user is logged in, and some configuration files specifying what type of user has access to each route.
I think Authorization and Authentication were not a good example, it’s a flop, sorry. The Components should be Domain related, they are BoundedContexts, and Authorization and Authentication are not domain. I will replace those examples immediately.
LikeLike
I think you need to make the distinction between authorising and authenticating (making sure this person is who clam to be and that he can actually access the part of the application he is trying to access) and managing you authentication and authorization (user registration, user login, managing user roles, …)
The latter can be seen as a (sub)domain of your application. However this is usually pretty generic and you can easily use an existing component to handle all of it, because why spend precious time reinventing and redesigning the wheel. Unless you have very specific needs which you can’t find in the existing components.
The former is in my opinion a concern of your (driving) adapter. It is (usually) not your application logic that should check wether the user is logged in, or has access to this specific command. It is the duty of your web controller (or even web framework) to handle this. I see it this way, because depending on where the request comes from, your access rules may vary. For example, when using the CLI, you could assume the user doesn’t need to be logged in, as he is an admin of your system. Or you may want some functionality to be accessible not only to a person logged in to your system, but also to someone logged in into an external admin system (like someone from a helpdesk who can edit a users account).
Sometimes it might seem to be a domain rule that some things can only be altered by the user who created this thing, but more often then not, this business rule doesn’t hold up when you start thinking about the part of the system, which can not be seen be a regular user.
LikeLiked by 1 person
I can’t find a place in my head for a proper authorization model. While ACL is a good separation (if I understand it correctly) – like if you have some particular role attached to you, then you can post to a blog, if don’t then you cant.
In my practice, there were more complex rules which transcend layers (app and domain layers.). You might need a specific role to make a domain action but also you need to meet some specific domain criteria.
For example, “You can post a comment if you have a “client” role AND you’ve purchased this product in the past”. This kind of rules involves specific domain logic to be executed.
So when you saying that “Authorization and Authentication are not domain”, I kind of disagree about authorization. Because Authorization can involve domain rules. Right?
I really want to learn effective ways to organize authorization logic in clean architecture. While I do understand all this layer&ports&adapters paradigm I feel like authorization part is often left undisclosed in many blog posts and books.
—
p.s. I haven’t read the latest Uncle Bob’s book on the subject. Perhaps there are some hints about authorization.
LikeLike
Sorry, I’ve missed your comment last week.
But to answer you, what you are talking about is not exactly Authorization in terms that I was talking about.
I was referring to Authorization in the sense of “Who can access what” platform-wide, which is basically a configuration that is set up in some config file, although to make it scalable we should use a generic ACL component.
What you are referring to is indeed business rules, not authorization in the sense of a platform-wide set of rules.
So those business rules do not belong in a generic Authorization component, it belongs in the component that needs it.
Going back to your example “You can post a comment if you have a ‘client’ role AND you’ve purchased this product in the past”, we only need this when the consumer issues a command to post a comment.
So, the way I see it, this is a specific rule for this specific use case (ie. “CreateProductComment”), of a specific component (ie. “ReviewComponent”).
We need to validate this rule but it is very specific.
Doing it quick and dirty, we can simply put an if statement in the command handler (or application service method).
Doing it a bit more scalable, we can create an authorization service specific to this component which will contain all the validation rules for all commands in the component.
Doing it a bit better, we could have a configuration setup saying that a use case (command, or application service method) prior to running needs to be validated with some other class/method.
If we are using a Command Bus, this would be something that could be done there, with a validation middleware.
Depending on our concrete needs, we could also use a Specification pattern where we would put fine-grained business rules, in such a way that we could eventually create complex business rules in specification objects by composing them from other specification objects.
In any case, both the use case code and its validation rules belong together, in the same component, and it is not what is generally referred to as Authorization.
LikeLike
(I was not able to reply directly to the message you’ve replied to me with. Maybe the blog reached maximum comment depth)
Authorization
I see you separate the two: generic ACL authorization and business rules. It makes total sense to me to have a separated authorizer class attached to a command handler. In fact, I practiced it and it worked very well.
So to follow your logic, generic ACL lets administrator to manually assign roles to users and allow roles to perform certain actions. Once a user is allowed to make a command only then domain rules will perform additional validation against the command and maybe reject it due to some unmet restrictions. It is like a 2-level authorization.
Performance
I was recently asked on my blog (https://lessthan12ms.com/authorization-and-authentication-in-clean-architecture/#comment-3629170994) how to deal with performance and code separation. For example, an authorizer class and command handler both can query the same data to make the work. But since they are independent, we may end up with multiple database queries.
How do you design such things in your apps? Can you give some guidance on improving performance in “clean architecture” apps?
LikeLike
Glad my explanation helped you 🙂
About the performance related to repeating queries in different contexts of the application, I think the Application Core should not concern itself with it. I think that is something for the ORM to deal with.
Doctrine, for example, uses a 1st level cache that stores the objects that were already fetched from the DB. It also keeps track of what queries were executed and what objects they returned. This 1st level cache is up during the request and only in the end it flushes all changes to the DB. So it takes care of repeating queries.
Doctrine also has a 2nd level cache where it stores objects in redis and reuses that cache through several requests.
Nevertheless, what I think we need to be very careful with is the N+1 problem when we create our queries. There is not much the ORM can do to help us with that except for telling us that a query is being repeated.
LikeLike
Great article, I can’t wait to read more from you.
LikeLike
Love your post. Excellent reference material for some active topics for me.
This is how I’ve been architecting software projects for the past few years and I’ve been extremely happy with the results:
– Clean
– Extendable
– Flexible
– Predictable
– Scalable
At danger of treading into “Hammer & Nail” territory, I found this can be applied to pretty much every type of project, be it Desktop UI, Console, Web App, API, regardless of delivery mechanism, you name it. and virtually any programming language and framework.
I never liked how frameworks and libraries would take over your project structure and dependencies, as well as infiltrate your lingo and dictating your choices.
But with this approach it has become just a detail, sitting at the outside boundary of your app.
LikeLike
Thanks for your articles, I understand more about the patterns now.
But it seems all the backend patterns. How the frontend fit on the architecture? For example, in the single page application (React, Angular, …) where we have components with their own business logic (like validation, hide/show field based on properties? Should the UI have their own domain model/services?
LikeLike
Well, I’m not a frontender, but I feel these concepts are quite generic and usable in the frontend as well.
Just the other day I was discussing with the react native developer working with me and we decided to create an adapter for the backend API his application is using because if we need to switch to another API version he can easily create another adapter and have it working.
When it comes to the domain in the frontend, it depends. If it really is just a frontend app with no backend and domain logic, then we can create a domain model as well. But in a very small app, I don’t know if it is worth it, I can only judge case by case, we can not go into the hammer and nail approach.
As for “validation, hide/show field based on properties”, those are not domain concerns, those are just functionality used by the frontend. I would even regard them as language constructs that can just be used wherever. For example, PHP does not have a native function to create a Uuid, but it is a very innocuous thing, so I would just create a function to generate them and treat it as if it was part of the PHP core itself. At any point I could just change its implementation to use Uuid v3 or v4, or whatever.
I hope this helps, although as I said, I have no experience in frontend.
LikeLike
Have you ever implemented such patterns in any projects?
LikeLike
Yes, I have.
In big enterprise projects, for example one is a SaaS ecom platform with thousands of web-shops worldwide, another one is a marketplace, live in 2 countries with a message bus thats handles over 20 million messages per month.
LikeLike
Sounds awesome!
Regards,
Xu
LikeLike