This post is part of The Containerization Chronicles, a series of posts about Containerization. In them, I write about my experiments and what I’ve learned on Containerization of applications. The contents of this post might make more sense if you read the previous posts in this series.
Now that we have the project integrated with a Continuous Integration server, where we run the tests and report back to GitHub pull requests with the results of the test run and the coverage, we can deploy our project and make it available on the Internet.
We will do so with Heroku. I have chosen Heroku because it allows me to perform these experiments for free.
If you want to jump into the code, this is the tag for this post.
Heroku will keep our application up on the Internet for 30 minutes after the last request to it. After those 30 minutes, it will go to “sleep” until a request to it is made. At that point, it will take some 20 seconds to wake up and gives us a response, but that’s fine, these are just experiments.
After creating our account on Heroku, we need to create a pipeline. We will call it ppln-explicit-arch-php-sfn. By default, a pipeline will have two environments:
- staging: where our Product Owner (PO) can test the application manually;
- production: where all our users can reach the application.
The workflow with Scrutinizer and Heroku
What we would like to have is a workflow in this format:
- Developers work on a task locally;
- The feature is regularly pushed to GitHub for safekeeping;
- When the task is ready, the developer makes a pull request (PR) to master;
- The PR triggers the tests in Scrutinizer;
- If the tests are green, it triggers a deploy to a Heroku app on staging;
- The PR is reviewed;
- The staging feature is accepted by the PO;
- The developer merges the PR to the master branch;
- The merge to master triggers the tests in Scrutinizer again (because new changes to the master branch, made in the meantime, might break our code);
- If the tests are green, Scrutinizer triggers a deploy to production.
For this, we need to limit Scrutinizer to monitoring only the master branch, so that only PRs and merges to master would trigger test runs and deployments. Otherwise, we would have Scrutinizer running tests and maybe deployments when it’s not needed, eventually creating a job queue and slowing down the whole process.
A challenge: Scrutinizer limitation as a CI
Unfortunately, Scrutinizer doesn’t trigger deployments when we make a PR, although it does trigger the tests run.
This means that we can not use PRs for deployment to staging, so the alternative is to use pushes to specific branches in order to trigger deployments to staging. We will make it so that whenever we make a push to a branch starting with stg-, Scrutinizer will deploy to a staging app on Heroku.
And this, however, means two things:
- We don’t need Scrutinizer to monitor PRs;
- We need Scrutinizer to monitor all branches, instead of only master, which will make Scrutinizer run the tests for all branches we create on GitHub 😦 .
This is, of course, a workaround. It’s not nice. I don’t particularly like it. But I also don’t want to put time investigating another CI engine at this moment, although I will surely do it at a later time.
So the actual workflow will be:
- Developers work on a task locally;
- The feature is regularly pushed to GitHub for safekeeping;
- When the task is ready, the developer makes a pull request (PR) to master;
- The PR triggers the tests in Scrutinizer;
- The PR is reviewed;
- When the review is green, the developer pushes to a branch starting with
stg-, which triggers the tests and a deployment to staging; - The staging feature is accepted by the PO;
- The developer merges the PR to the master branch;
- The merge to master triggers the tests in Scrutinizer again (because new changes to the master branch, made in the meantime, might break our code);
- If the tests are green, Scrutinizer triggers a deploy to production.
Scrutinizer config
For the workflow above we need to configure Scrutinizer as follows, on their website:
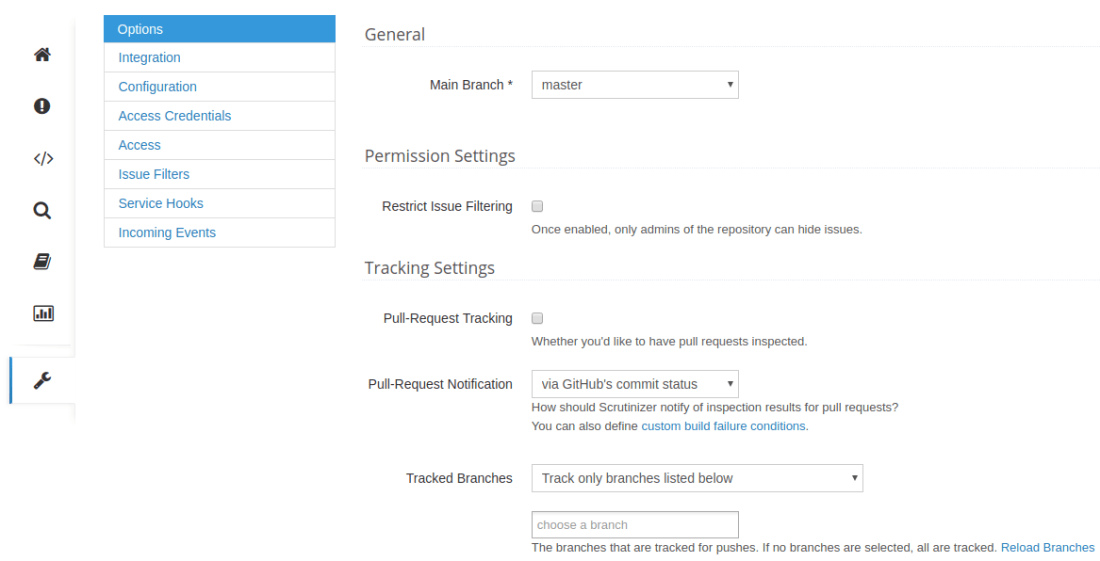
As you can see above, we are not tracking PRs nor any specific branches.
In our .scrutinizer.yml config we will need to add a snippet so that Scrutinizer knows we want to deploy to Heroku:

This tells Scrutinizer that every time there is a merge/push to a branch starting with stg- it needs to run the command make deploy_stg-ci, and whenever there is a merge/push to master, it needs to run the command make deploy_prd-ci.
The deployment script
Now we need to create those commands in our Makefile. I started by creating those commands directly in the Makefile, but it turned out to be too complex to just put them in the Makefile, so I created a reusable deployment script in bash and call it from the Makefile.
The deployment script goes like this:

The script receives two arguments, the first is the stage of the Heroku app in the pipeline (either staging or production), and the second is the Heroku app name, which will be the same as the branch being deployed.
The script will get the variables in a brown background from the environment, so we need to make sure the environment where the script runs has them in the environment. Since this script will run in the CI, we need to set those environment variables in Scrutinizer, and since we don’t want to have those variables in the repository (for security reasons and so that they can be changed without redeploying the app) we will add them in the Scrutinizer web config, as opposed to the yaml config:

The Makefile additions are trivial:

Running the application in Heroku
If we take a look at the deployment script above, we will notice that when we deploy to Heroku, we simply send a docker image to the Heroku registry.
The only thing Heroku does is start the container, so whatever the container entry point is, that’s what will be running. This seems sensible, but Heroku brings up the container making our application listen on a random port every time and makes that port available in the environment.
Our image current entry point is set in the production image dockerfile:

As we can see, the port where our application listens is hardcoded there, and we need to make it be in sync with what Heroku puts in the environment variable.
As stated in the Docker documentation, we can simply do this:

Unfortunately, I couldn’t make this work!! (if you know how to make it work, please let me know!!) So I needed to create a script that the dockerfile will reference and that script will be able to get the port from the environment.
The script to bring the application up is as follows:

And we change the dockerfile accordingly:

This is it.
Please, feel free to share your thoughts and/or ways to improve this.

2 thoughts on “Deployments with containers”