This post is part of The Containerization Chronicles, a series of posts about Containerization. In them, I write about my experiments and what I’ve learned on Containerization of applications. The contents of this post might make more sense if you read the previous posts in this series.
This is a fairly small post, as it is really simple to integrate with CodeCov. Follow the instructions on their website to create your account and set up the repository and follow along with this post.
To be honest, we don’t even really need this integration at this point, because Scrutinizer can already give us a nice badge for the code coverage, as well as fail the build if the coverage degrades. Nevertheless, CodeCov gives us all that plus a much more detailed report about the coverage than just the final coverage rating, and the possibility to fail the build if the coverage of the pull request is below the limit, or results in a global coverage below the limit.
If you want to jump right into the code, this is the tag on GitHub.
Furthermore, in a big enterprise application, the test suite will be big and slow, and it will be even (much) slower if we run it generating the code coverage. This will become cumbersome when we need to wait for the scrutinizer status to be published to GitHub so that we can merge a pull request.
So, in such a project, I would say that the ideal would be to use scrutinizer only for code quality analysis, while some other tool would run the tests, and some other tool would generate the code coverage and send it to CodeCov. All this happening in parallel, of course, so that there is less chance of a PR stalling while waiting for a status check to arrive to GitHub.
First, we add to our Makefile the command to publish the coverage report:

Next, we add the make command to publish the coverage report, in the scrutinizer configuration:

After running the tests, we send the report to CodeCov. The disadvantage of this is that if the publishing fails, scrutinizer will report to GitHub that the tests failed, which is not the case.
Finally, we add the nice badge to our repository readme:


The last thing to do is integrating with GitHub. At this moment, we already have a CodeCov report in our pull requests, like this:

But we can also add status checks requirements to merge a PR:

The status check codecov/patch will give us the coverage rating for the files touched in the PR, and the codecov/project will give us the global coverage rating of the project.
The actual target coverage requirement by default is 80%, but we can change it by adding a .codecov.yml in the root of our project. We can read about all the options on the CodeCov GitHub Wiki, but it’s worth saying that adding this yaml file is completely optional and the default values should be enough for most cases.
For now, we will add this configuration:
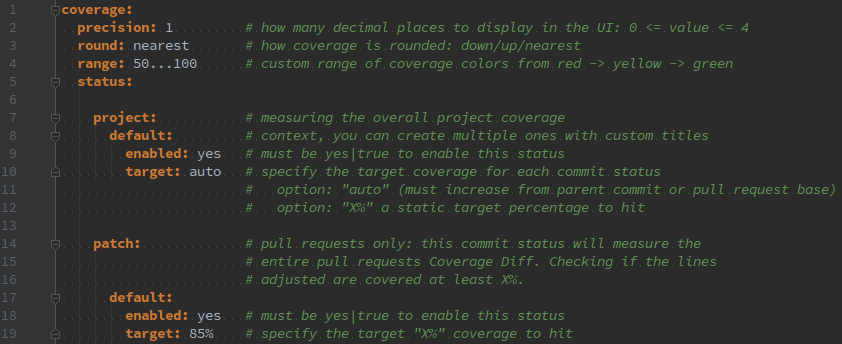
Which we can validate with cat .codecov.yml | curl --data-binary @- https://codecov.io/validate.
In the end, our pull requests will have something like this:

That’s all there is to it!
Please, feel free to share your thoughts and/or ways to improve this.

One thought on “Integration with CodeCov”