This post is part of The Software Architecture Chronicles, a series of posts about Software Architecture. In them, I write about what I’ve learned on Software Architecture, how I think of it, and how I use that knowledge. The contents of this post might make more sense if you read the previous posts in this series.
The SOA Style has been around since the late 1980s and has its origins in ideas introduced by CORBA, DCOM, DCE and others. Much has been said about SOA, and there are a few different implementation patterns but, in essence, SOA focuses on only a few concepts and doesn’t give any prescription on how to implement them:
- Composability of user-facing applications;
- Reusable Business Services;
- Technology stack independent;
- Autonomy (independent evolution, scalability & deployability).
SOA is a set of architectural principles independent of any technology or product, just like polymorphism and encapsulation are.
In this post I am going to address the following patterns related to SOA:
- CORBA – Common Object Request Broker Architecture
- Web Services
- Message Queue
- Enterprise Service Bus (ESB)
- Microservices
CORBA – Common Object Request Broker Architecture
During the 1980s, derived from the growing usage of enterprise networks and the client/server architecture, there was an increasing need for a common way of getting applications that were built using different technologies and were running on different computers with a different OS, to communicate. CORBA was developed to fulfil those needs. It is a standard, for Distributed Computing, that developed during the 1980s and reached its first mature version 1991.
The CORBA standard was implemented by several vendors and aimed at providing:
- Platform neutral Remote Procedure Call;
- Transactions (also remote transactions!!);
- Security;
- Events;
- Programming language independence;
- OS independence;
- Hardware independence;
- Isolation from data-transfer/communication details;
- Data typing through an Interface Definition Language (IDL).
At the moment CORBA is still used for heterogeneous computing, for example, it is still part of JAVA EE, although it will be packaged as a separate module from JAVA 9 onwards.
It’s important to note, though, that I don’t consider CORBA to be an SOA pattern (although I do consider both CORBA and SOA patterns to be under the umbrella of distributed computing). I chose to include it here because I feel it was its shortcomings that led to the SOA movement.
How it works
First, we need to acquire an Object Request Broker (ORB), which conforms to the CORBA specification, it is supplied by a vendor and it uses language mappers to generate stubs and skeletons in the client code languages. Using that ORB and the interface definitions defined using an IDL (similar to a WSDL), in the client, we generate stub classes of the real classes that can be called remotely and, in the server, we generate skeleton classes that can handle incoming requests and make the call to the real target object.
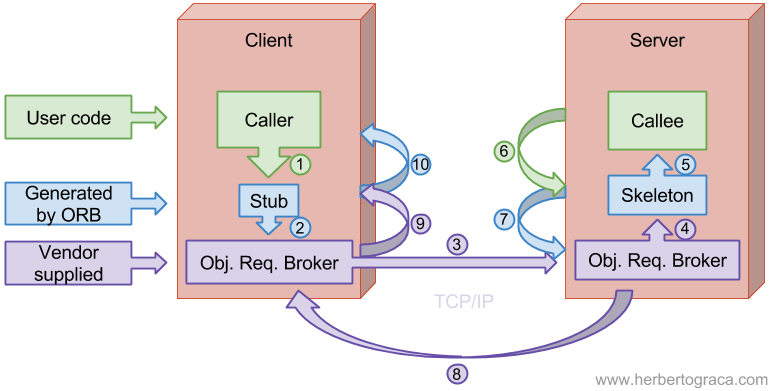
- The caller calls a local procedure implemented by the stub;
- The stub validates the call and creates a request message that passes to the ORB;
- The client ORB sends the message over the network to the server and blocks the current execution thread;
- The server ORB receives the request message and instantiates the skeleton;
- The skeleton executes the procedure on the called object;
- The called object performs a computation and returns the result;
- The skeleton packs the output arguments into a response message and passes it to the ORB;
- The ORB sends the message over the network back to the client;
- The client ORB receives the response message, unpacks it and delivers it to the stub;
- The stub passes output arguments to the caller, releases execution thread and the caller continues in execution.
Pros
- Tech stack independence (except for the ORB implementation);
- Isolation from data-transfer/communication details.
Cons
- Location transparency: The client code does not know if a call is local or remote. This sounds like a good thing, however, the latency and type of failures are quite different, depending if it’s a local or remote call. Not knowing what type of call it is, makes it impossible for applications to choose an appropriate strategy to handle the method call, and to end up making remote calls inside a loop, and therefore considerably slowing down the whole system.
- Complex, redundant and ambiguous specification: It was created as a mash-up of several existing vendor versions, so (at that time) it was ambiguous and redundant, making it difficult to implement.
- Blocked communication pipes: It used specific protocols over TCP/IP and specific ports, or even random ports. But enterprise security rules and firewalls would often only allow for HTTP communication over port 80, effectively blocking CORBA communication.
Web Services
Although CORBA still has its use cases nowadays, we learned that we needed to reduce the remote communications to make the system more performant, we needed a reliable communication pipe, and we needed a simpler communication specification.
Thus, during the late 1990s, web services started to spawn with the goals of solving the problems mentioned above:
-
We needed a reliable communication pipe, so:
- HTTP through port 80 is the default communication pipe;
- An agnostic communication language is used (like XML or JSON);
-
We needed to reduce the remote communications, so:
- We have explicit remote communications so that we know exactly when we are making a remote call;
- We have coarse-grained remote calls, ie. instead of calling remote objects often, we call a remote service less often;
-
We needed a simpler communication specification, so:
- SOAP had its first draft in 1998 and reached a W3C recommendation in 2003, making it effectively a standard. It embodied some of the ideas of CORBA, like a layer to handle the communication and a “document” defining the interfaces using a Web Services Description Language (WSDL);
- REST was defined in 2000, by Roy Fielding in his PhD dissertation “Architectural Styles and the Design of Network-based Software Architectures“, and it is a much simpler specification than SOAP which made it quickly gain higher adoption than the slightly older SOAP specification.
- GraphQL was developed by Facebook in 2012 and released to the public in 2015. It is an API query language that allows the client to specify exactly what data the server should send back, as opposed to an ad-hoc payload, avoiding both over-fetching and under-fetching data.
[Web] Services can be published, discovered and used in a technology neutral, standard form.
Microsoft 2004, Understanding Service-Oriented Architecture
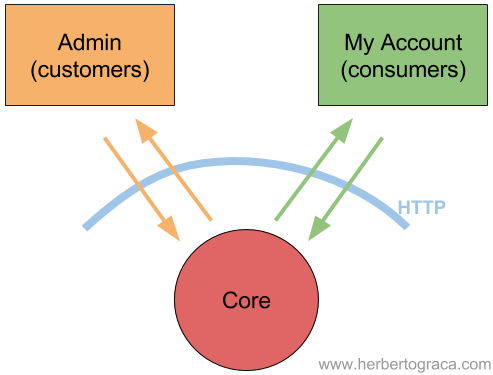
Through Web services, SOA makes a paradigm shift from one of remotely invoking methods on objects (CORBA), to one of passing messages between services.
We need to understand, though, that under the umbrella of SOA, a web service is not just a general purpose API, which simply provides CRUD access to its database through HTTP. While that implementation might be useful in some cases, it requires that users understand the underlying model and comply with the business rules to ensure that your data integrity is protected. SOA implies that web services are designed as bounded contexts for business sub-domains, abstracting the implementation from the conceptual service they provide.
SOA is not just an architecture of services seen from a technology perspective, but the policies, practices, and frameworks by which we ensure the right services are provided and consumed.
Microsoft 2004, Understanding Service-Oriented Architecture
Pros
- Independent tech stack, deployment and scalability of services;
- Common, simple and reliable communication channel (text through HTTP, port 80);
- Optimised communication;
- Stable communication specification;
- Insulation of Domain contexts.
Cons
- Difficult integration of different web services, due to different communication languages, ie. two web services that use different JSON representations of the same concept;
- Synchronous communication can overload the systems.
Message Queue
The core idea is to have several applications communicating asynchronously between them, using agnostic messages. The Message Queue provides for improved scalability and higher decoupling between the applications as they don’t need to know where the other applications are located, how many and not even who they are. Despite this, they all need to use the same communication language, ie a predetermined text format to represent data.
A Message Queue uses a message broker software (ie. RabbitMQ, Beanstalkd, Kafka, …) as an infrastructure artefact and can be set up in different ways to implement the communication between applications:
- Request/Reply
- A client sends a message to the Message Queue, including a “conversation” reference. The message is delivered to a specific node, which will reply with another message, to the original sender, containing the same conversation reference so that the receiver knows to what conversation the message refers to and it can continue the process. It’s very useful for medium and long-running business processes (sagas).
- Publish/Subscribe
- List-Based
It maintains lists of published topics and subscribers to those topics. As it receives messages for a topic it puts the message into the corresponding topic list. Matching the message to a topic can be done by the message type or with a more complex set of predetermined criteria that can include the message content itself. - Broadcast-Based
As it receives messages, it broadcasts them to all the nodes that are listening to the queue. Each listening node is responsible for filtering and processing only the messages that it is interested in.
- List-Based
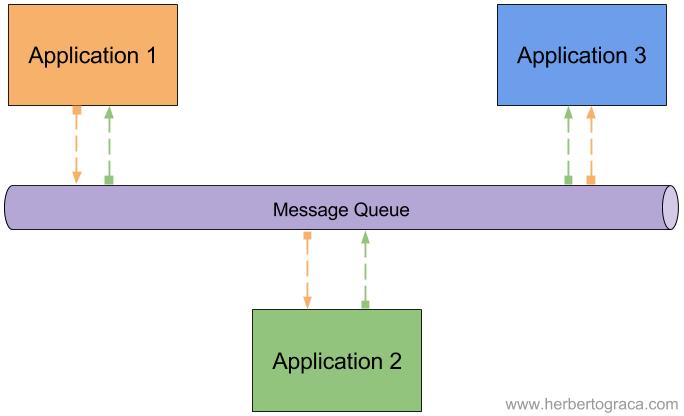
All these patterns can be set up in a pull (aka polling) or push approach:
- In a pull scenario, the client will ask the queue for a message at every X amount of time. This has the benefit that the client is able to control its load but also might have the downside of introducing latency, ie. when there are messages on the queue and the client is not handling messages but just waiting for the moment to poll for a new message;
- In a push scenario, the queue will push messages to clients as soon as a message is received. The advantage here is that there is no latency, but the clients can not self-manage their load.
Pros
- Independent tech stack, deployment and scalability of services;
- Common, simple and reliable communication channel (text through HTTP, port 80);
- Optimised communication;
- Stable communication specification;
- Insulation of Domain contexts;
- Easy attachment and detachment of services;
- Asynchronous communication helps manage the system’s load.
Cons
- Difficult integration of different web services, due to different communication languages, ie. two web services that use different JSON representations of the same concept;
Enterprise Service Bus (ESB)
During the 1990s, at the same time that the Web Services were evolving, the Enterprise Service Bus was already making use of them (maybe some implementations even used CORBA initially?).
The ESB came to life in a context where the companies had their stand-alone applications, like one application for finance, another one for human resources, another one for stock management, etc., and they needed to make those applications communicate with each other, they needed to integrate them. But those applications had not been thought with integration in mind, there was no common language format for applications to communicate (as there isn’t one today). So the reasonable solution was for the application vendors to create endpoints to send and receive data in a specific format. The client companies would then have to integrate the applications by establishing a communication pipe and translate the messages from one application language to another.
The Message Queue could contribute to solving this problem, but it still could not solve the problem of applications having different language formats. Nevertheless, it was a small step to change the Message Queue from a dumb communication channel into a middleware that handles both delivering messages and their transformation into the language/format expected by the receiver. The ESB was a natural evolution of the simpler Message Queue.

In this architecture type, we have composite applications, typically user-facing, that contact web services to perform some operation. This web services, in turn, can also contact other web services and in the end, they may return some data back to the composite application. However, both the composite application and the back-end services have no knowledge of the details of each other, namely their location or communication protocols. What they do know is what service they need and the location of the Service Bus.
So the client application (be it a service or a composite application) sends its request to the Service Bus, which in turn transforms the message into the format expected by the destination and routes the request to the destination. It’s important to note that all communication goes through the ESB, which means that if the ESB goes down, all communications go down and all systems are rendered inoperative. In the end, an ESB works like a middleware where a lot of things happen, rendering it a highly complex artefact.
This was, of course, a very basic explanation of what an ESB architecture is. Furthermore, although the ESB is the main artefact in this architecture, there can be other artefacts involved, like Domain Brokers, Data Services, Process Orchestration Services or Rules Engines. This same architecture pattern can also be set up in a federated design, where the system is segregated in business domains, each with its own ESB setup and all of those setups connected between them. This helps to improve performance and mitigate the problem of having a single point of failure, ie. if one ESB fails, only its business domain will be affected.

The primary duties of an ESB are:
- Monitor and control routing of message exchange between services;
- Resolve translation of messages between communicating service components;
- Control deployment and versioning of services;
- Marshal use of redundant services;
- Cater for commodity services like event handling, data transformation and mapping, message and event queuing and sequencing, security or exception handling, protocol conversion and enforcing proper quality of communication service;
When building communication structures between different processes, we’ve seen many products and approaches that stress putting significant smarts into the communication mechanism itself. A good example of this is the Enterprise Service Bus (ESB), where ESB products often include sophisticated facilities for message routing, choreography, transformation, and applying business rules.
Martin Fowler 2014, Microservices
This architecture pattern has advantages but I find it especially useful if we don’t “own” the web services and therefore need a middleware to translate the messages between them, orchestrate business processes involving several web services, etc..
It’s also good to keep in mind that the ESB implementations have evolved and today we can even use a simple drag & drop UI to configure an ESB, for most use cases.
Pros
- Independent tech stack, deployment and scalability of services;
- Common, simple and reliable communication channel (text through HTTP, port 80);
- Optimised communication;
- Stable communication specification;
- Insulation of Domain contexts;
- Easy attachment and detachment of services;
- Asynchronous communication helps manage the system’s load;
- Single point for versioning and translation management.
Cons
- Slower communication speed, especially for those already compatible services;
- Centralised logic:
- Single point of failure that can bring down all communications in the Enterprise;
- High configuration and maintenance complexity;
- In time the ESB can end up containing business rules;
- Due to its complexity it will eventually need a team just to manage it;
- Services become highly dependent of the ESB.
Microservices
The Microservices Architecture has its foundations on the SOA concepts, and shares the same global goals as the ESB: Creating one global enterprise application from several more specific business domain applications.
The key difference is that the ESB was born into a context of stand-alone applications that needed to be integrated in order to achieve an enterprise-wide distributed application, while the Microservices Architecture was born into a context of fast paced and ever changing businesses who (mostly) create their own cloud applications from scratch.
In other words, the starting point is different. In the case of the ESB, we start with existing applications which we do not “own”, and therefore we can not change them. But with the Microservices, we have full control over the application(s) (which doesn’t mean there can’t be any 3rd party web services involved in the system).
The way microservices are built/designed prevents a high need for integration. Microservices should be specific to a business concept, to a bounded context, they should keep their own state so that they don’t depend directly on other microservices and therefore need less integration. In other words, the low coupling and high cohesion provided by microservices have the nice side effect of reducing the need for integration.
[Microservices are] Small autonomous services that work together, modelled around a business domain.
Sam Newman 2015, Principles Of Microservices
Since the biggest drawback of the ESB Architecture was the very complex and central application of which all other applications would depend on, the Microservices Architecture addresses that problem by removing it almost completely.
There are still elements that are cross-cutting to the whole microservices ecosystem, but they don’t contain so many responsibilities as the ESB would contain. For example, there still is a Message Queue used for asynchronous communication between microservices, but it is simply a message pipe with no other responsibilities. Another example is the microservice ecosystem gateway through which all communications with the outside are made.
Sam Newman, the author of Building Microservices, identifies 8 principles of a Microservices Architecture:
- Services are modelled around business domains
Because it can give us stable interfaces around a business concept, very cohesive and decoupled units of code and clearly identified bounded contexts; - Culture of automation
Because we will have a lot more moving parts and deployable units; - Hide implementation details
To allow one service to evolve independently of another; - Decentralise all the things
Decentralise the decision making power and the architectural concepts, giving autonomy to the teams so that the organisation transforms itself into a Complex Adaptative System who can quickly adapt to change; - Deploy independently
So that we can deploy a new version of a service without the need to change anything else; - Consumer first
A service should be easy to consume, easy to be used by other services; - Isolate failure
So that even if one service fails, the others continue to operate, giving the overall system a high resilience to failure; - Highly observable
Due to the system high number of parts, it is more difficult to understand everything that is going on, so we need sophisticated monitoring tools that allow us to know what is going on in every corner of the system and understand any chain reactions.
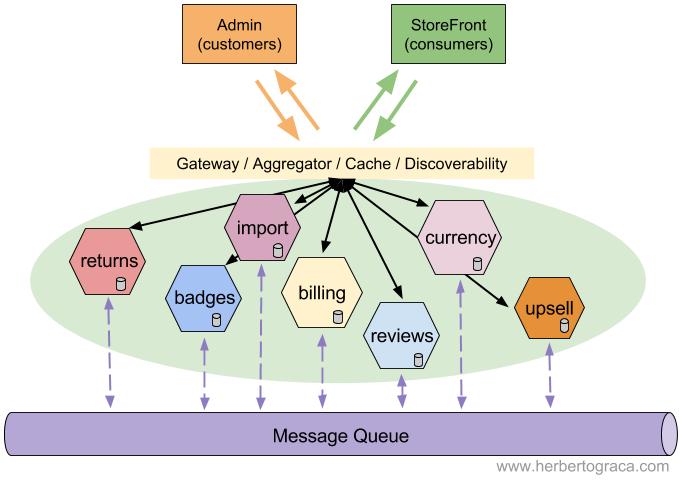
The microservice community favours an alternative approach: smart endpoints and dumb pipes. Applications built from microservices aim to be as decoupled and as cohesive as possible – they own their own domain logic and act more as filters in the classical Unix sense – receiving a request, applying logic as appropriate and producing a response. These are choreographed using simple RESTish protocols rather than complex protocols such as WS-Choreography or BPEL or orchestration by a central tool.
Martin Fowler 2014, Microservices
Pros
- Independent tech stack, deployment and scalability of services;
- Common, simple and reliable communication channel (text through HTTP, port 80);
- Optimised communication;
- Stable communication specification;
- Insulation of Domain contexts;
- Easy attachment and detachment of services;
- Asynchronous communication helps manage the system’s load;
- Synchronous communication helps manage the system’s performance;
- Truly independent and autonomous services;
- No business logic outside of the services;
- Potential to transform the organisation into a Complex Adaptative System, composed of several small autonomous parts/teams who can quickly adapt to business changes.
Cons
- High operational complexity:
- Needs high investment in a strong DevOps culture;
- Using a multitude of technologies and libraries can get out of hand;
- Input and output API changes must be managed carefully because there will be software relying on those interfaces;
- The usage of eventual consistency has significant implications that must be addressed while developing the application, all the way from the back-end to the UX layers;
- Testing becomes more complex as interface changes can have unpredictable consequences in other services.
Anti-Pattern: Ravioli Architecture

Ravioli Architecture is the name commonly used to refer to the anti-pattern for Microservices Architecture. It happens when we end up creating an ecosystem of micro-services where they are too many, too small and don’t represent domain concepts on their own.
Conclusion
SOA has evolved a lot in the last decades and, derived from both the insufficiencies of the implemented solutions and the technological advances, we have reached the Microservices Architecture.
The idea behind this whole evolution has always been the usual strategy used to solve complex problems: break the problem into smaller, solvable pieces.
Solving the code complexity can also be done in the same way when we have a monolith, breaking it up into decoupled domain components (bounded contexts). But, as the teams and the codebase grows, so does the need for independent evolution, scalability & deployability. SOA provides the tools for this independence, forcing stricter boundaries between bounded contexts.
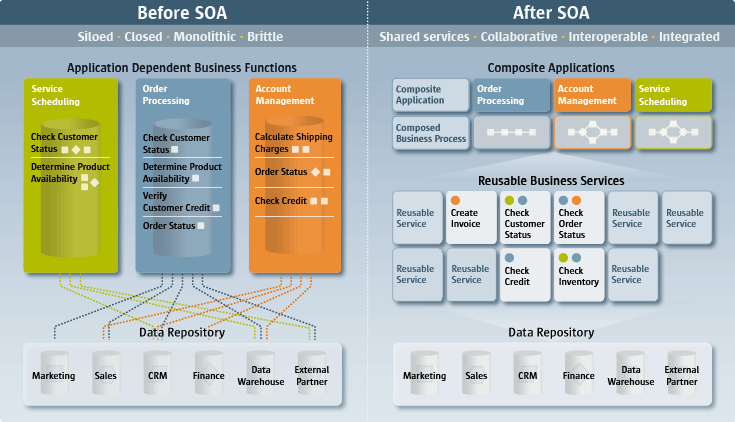
Once more, it’s about low coupling and high cohesion, this time at an even coarser granularity than before. It’s also, again, fundamental to analyse our needs with pragmatism: use SOA only when we really need to, because it brings a lot of complexity to the mix, and if we do really need to use SOA let’s create Microservices in the size and quantity that really fit our needs, no more, no less.
Sources
1997 – Steve Vinoski – CORBA: Integrating Diverse Applications Within Distributed Heterogeneous Environments
2000 – Roy Fielding – Architectural Styles and the Design of Network-based Software Architectures
2004 – Microsoft – Message Bus
2004 – Microsoft – Understanding Service-Oriented Architecture
2011 – Chris Ostrowski – Understanding Oracle SOA – Part 1 – Architecture
2011 – Chris Ostrowski – Understanding Oracle SOA – Part 2 – Technologies
2011 – Chris Ostrowski – Understanding Oracle SOA – Part 3 – Development
2011 – Chris Ostrowski – Understanding Oracle SOA – Part 4 – Business Benefits
2012 – Prabhu – Service Oriented Architecture – SOA
2014 – Martin Fowler – Microservices
2014 – PWC – Agile coding in enterprise IT: Code small and local
2015 – Udi Dahan – Messaging Architecture and Services Bus
2015 – Sam Newman – Principles Of Microservices
2016 – Kai Wähner – Microservices: Death of the Enterprise Service Bus?
2016 – Abraham Marín Pérez – Java 9 Will Remove CORBA from Default Classpath
2016 – Oracle – CORBA Technology and the Java™ Platform Standard Edition
2017 – Wikipedia – Distributed object communication
2017 – Wikipedia – Common Object Request Broker Architecture
2017 – Wikipedia – Enterprise service bus
2017 – Wikipedia – Representational State Transfer
2017 – Wikipedia – SOAP
2017 – Wikipedia – Service-oriented architecture
2017 – Microsoft – Enterprise Architecture: SOA in the real world
Translations
- Vietnamese, by Edward Hien Hoang

Architects should know the dynamics of the pattern. Once the architect knows the aspects he can choose a relevant pattern that helps effectively resolve the problem (instead of reinventing the wheel)
LikeLike
How does Reactive Architecture fits on it?
LikeLike
Well, I’m not experienced with Reactive Architecture so my thoughts about it are not worth much…
Nevertheless, I can say that I think it should not make much difference for the architecture style because the main difference is that the communication pipeline between frontend/backend is done through web-sockets. However, we might need to use different architectural patterns to make the web-sockets work, but, again, I’m not experienced with implementing reactive architectures so my opinion on this does not cary much weight.
Thanks for your question, though. I am currently coding an example of this architecture and this is indeed an interesting use case to build! I will add it to my planned post list! ☺
LikeLike
Love the article, our business is currently half ESB half ravioli, which makes it even worse.
The need for an SOA is too high. Migrating might take a few years, maybe by then we have moved on from microservices, The main difficulty with micro services is Data Protection, authorization and validation, to protect your business logic and your data (and your personal sanity).
LikeLike