This post is part of The Software Architecture Chronicles, a series of posts about Software Architecture. In them, I write about what I’ve learned on Software Architecture, how I think of it, and how I use that knowledge. The contents of this post might make more sense if you read the previous posts in this series.
When creating an application, the easy part is to build something that works. To build something that has performance despite handling a massive load of data, that is a bit more difficult. But the greatest challenge is to build an application that is actually maintainable for many years (10, 20, 100 years).
Most companies where I worked have a history of rebuilding their applications every 3 to 5 years, some even 2 years. This has extremely high costs, it has a major impact on how successful the application is, and therefore how successful the company is, besides being extremely frustrating for developers to work with a messy code base, and making them want to leave the company. A serious company, with a long-term vision, cannot afford any of it, not the financial loss, not the time loss, not the reputation loss, not the client loss, not the talent loss.
Reflecting the architecture and domain in the codebase is fundamental to the maintainability of an application, and therefore crucial in preventing all those nasty problems.
Explicit Architecture is how I rationalise a set of principles and practices advocated by developers far more experienced than me and how I organise a code base to make it reflect and communicate the architecture and domain of the project.
In my previous post, I talked about how I put all those ideas together and presented some infographics and UMLish diagrams to try to create some kind of a concept map of how I think of it.
However, how do we actually put it to practice in our codebase?!
In this post, I will talk about how I reflect the architecture and the domain of a project in the code and will propose a generic structure that I think that can help us plan for maintainability.
My two mental maps
In the last two posts of this series I explained the two mental maps I use to help me think about code and organise a codebase, at least in my head.
The first one is composed by a series of concentric layers, which in the end are sliced to make up the domain wise modules of the application, the components. In this diagram, the dependency direction goes inwards, meaning that outer layers know about inner layers, but not the other way around.
The second one is a set of horizontal layers, where the previous diagram sits on top, followed by the code shared by the components (shared kernel), followed by our own extensions to the languages, and finally the actual programming languages in the bottom. Here, the dependencies direction goes downwards.
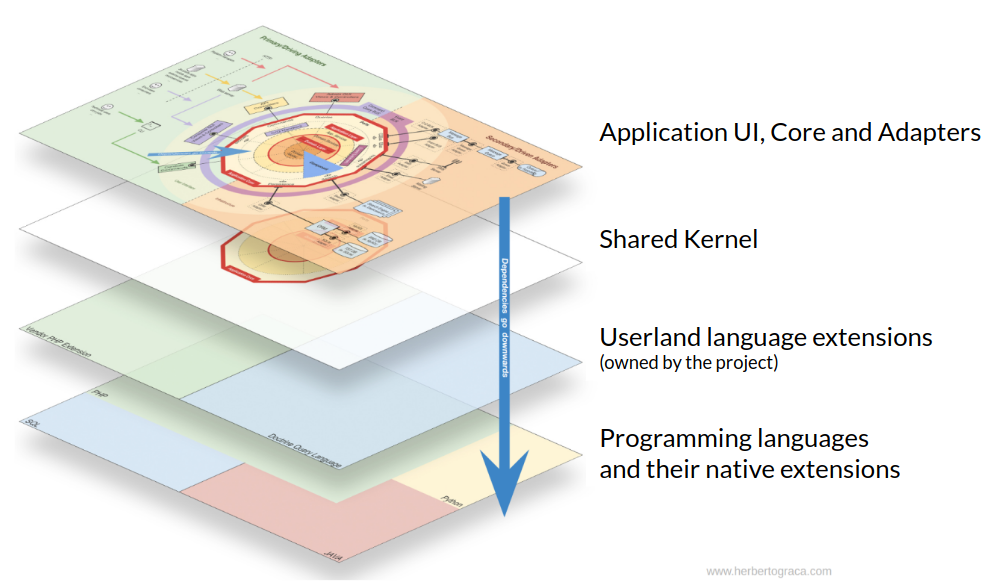
Architecturally evident coding style
Using an architectureally evident coding style means that our coding style (coding standards, class, methods and variables naming conventions, code structure, …) somehow comunicates the domain and the architecture to who is reading the code. There are two main ideas on how to achieve an architecturally evident coding style.
“[…] an architecturally evident coding style that lets you drop hints to code readers so that they can correctly infer the design.”
George Fairbanks
The first one is about using the code artefacts (classes, variables, modules, …) names to convey both domain and architectural meaning. So, if we have a class that is a repository dealing with invoice entities, we should name it something like `InvoiceRepository`, which will tell us that it deals with the Invoice domain concept and its architectural role is that of a repository. This helps us know and understand where it should be located, plus how and when to use it. Nevertheless, I think we don’t need to do do it with every code artefact in our codebase, for example I feel that post-fixing an entity with ‘Entity’ is redundant and just adds noise.
“[…] the code should reflect the architecture. In other words, if I look at the code, I should be able to clearly identify each of the components […]”
Simon Brown
The second one is about making sub-domains explicit as top level artefacts of our codebase, as domain wise modules, as components.
So, the first one should be clear and I don’t think it requires any further explanation. However, the second one is more tricky, so lets dive into that.
Making architecture explicit
We’ve seen, in my first diagram, that at the highest zoom level we have 3 different types of code:
- The user interface, containing the code adapting a delivery mechanism to a use case;
- The application core, containing the use cases and the domain logic;
- The infrastructure, containing the code that adapts the tools/libraries to the application core needs.
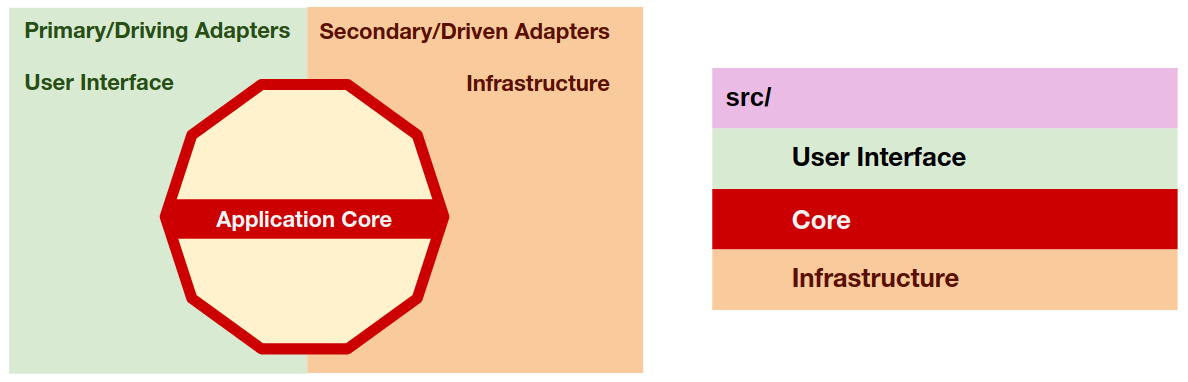
So at the root of our source folder we can reflect these types of code by creating 3 folders, one for each type of code. These three folders will represent three namespaces and later on we can even create a test to assert that both the user interface and the infrastructure know about the core, but not the other way around, in other words, we can test that the dependencies direction goes inwards.
The user interface
Within a web enterprise application, it is common to have several APIs, for example a REST API for clients, another one for web-hooks used by 3rd party applications, maybe a legacy SOAP API that still needs to be maintained, or maybe a GraphQL API for a new mobile app…
It is also common for such applications to have several CLI commands used by Cron jobs or on demand maintenance operations.
And of course, it will have the website itself, used by regular users, but maybe also another website used by the administrators of the application.
These are all different views on the same application, they are all different user interfaces of the application.
So our application can actually have several user interfaces, even if some of them are used only by non-human users (other 3rd party applications). Let’s reflect that by means of folders/namespaces to separate and isolate the several user interfaces.
We have mainly 3 types of user interfaces, APIs, CLI and websites. So lets start by making that difference explicit inside the UserInterface root namespace by creating one folder for each of them.
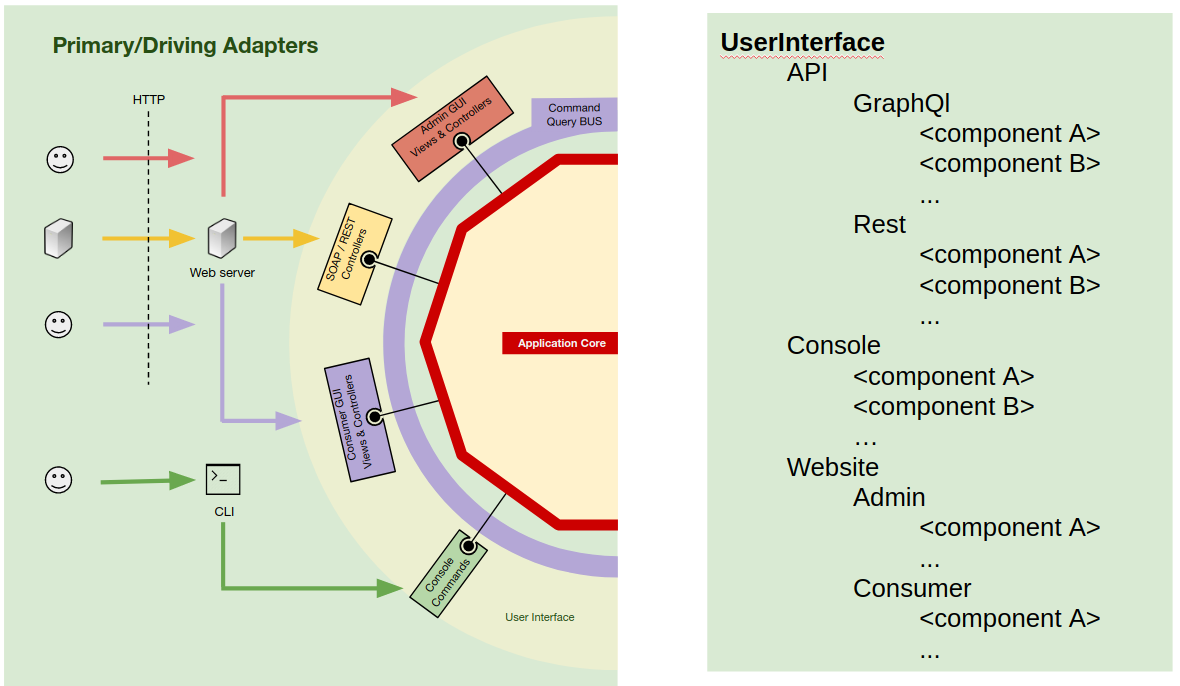
Next, we go deeper and inside the namespace for each type and, if needed, we create a namespace for each UI (maybe for the CLI we don’t need to do it).
The infrastructure
In a similar way as in the User Interface, our application uses several tools (libraries and 3rd party applications), for example an ORM, a message queue, or an SMS provider.
Furthermore, for each of these tools we might need to have several implementations. For example, consider the case where a company expands to another country and for pricing reasons its better to use a different SMS provider in each country: we will need different adapter implementations using the same port so they can be used interchangeably. Another case is when we are refactoring the database schema, or even switching the DB engine, and need (or decide) to also switch to another ORM: then we will have 2 ORM adapters hooked into our application.
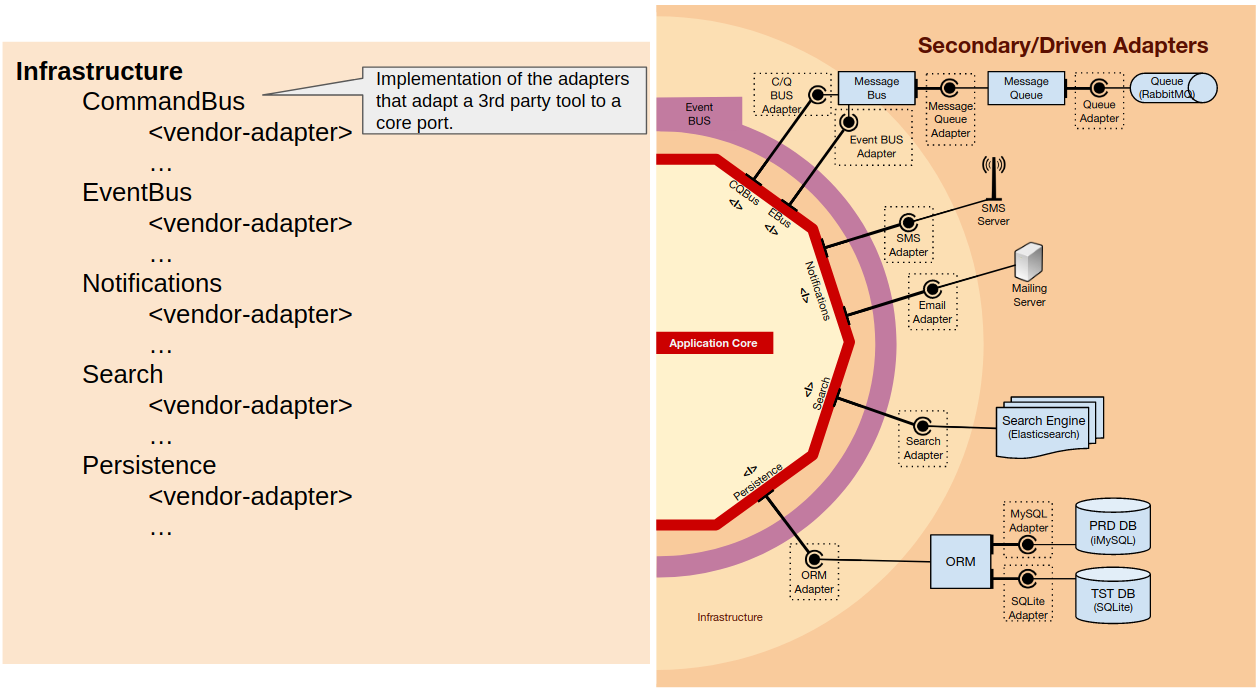
So within the Infrastructure namespace we start by creating a namespace for each tool type (ORM, MessageQueue, SmsClient), and inside each of those we create a namespace for each of the adapters of the vendors we use (Doctrine, Propel, MessageBird, Twilio, …).
The Core
Within the Core, at the highest level of zoom, we have three types of code, the Components, the Shared Kernel and the Ports. So, we create folders/namespaces for all of them.
Components
In the Components namespace we create a namespace for each component, and inside each of those we create a namespace for the Application layer and a namespace for the Domain layer. Inside the Application and Domain namespaces we start by just dumping all classes on there and as the number of classes grow, we start grouping them as needed (I find it overzealous to create a folder to put just one class in it, so I rather do it as the need for it arises).
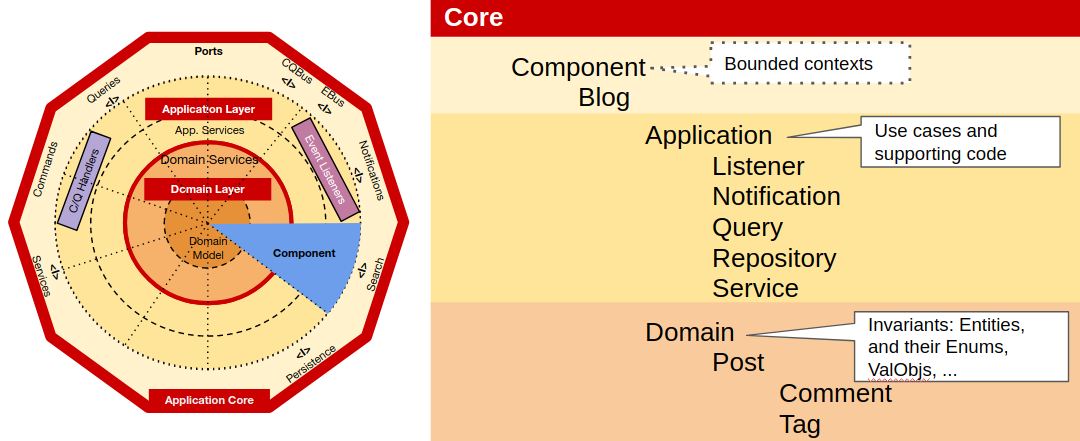
At this point we need to decide if we should group them by subject (invoice, transaction, …) or by technical role (repository, service, value object, …), but I feel that, whatever the choice, it doesn’t really have much impact because we are at the leafs of the organisation tree so, if needed, its easy to do changes to that last bit of structure without much impact to the rest of the codebase.
Ports
The Ports namespace will contain a namespace for each tool the Core uses, just like we did for the Infrastructure, where we will place the code that the core will use in order to use the underlying tool.
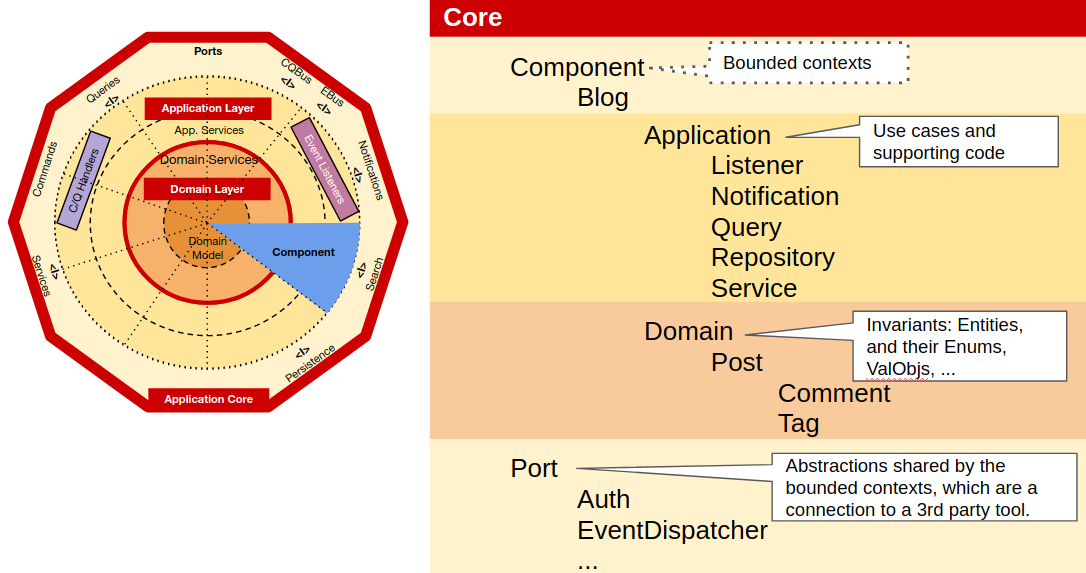
This code will also be used by the adapters, whose role is to translate between the port and the actual tool. It its simplest form, a port is just an Interface but in many cases it also needs value objects, DTOs, services, builders, query objects or even repositories.
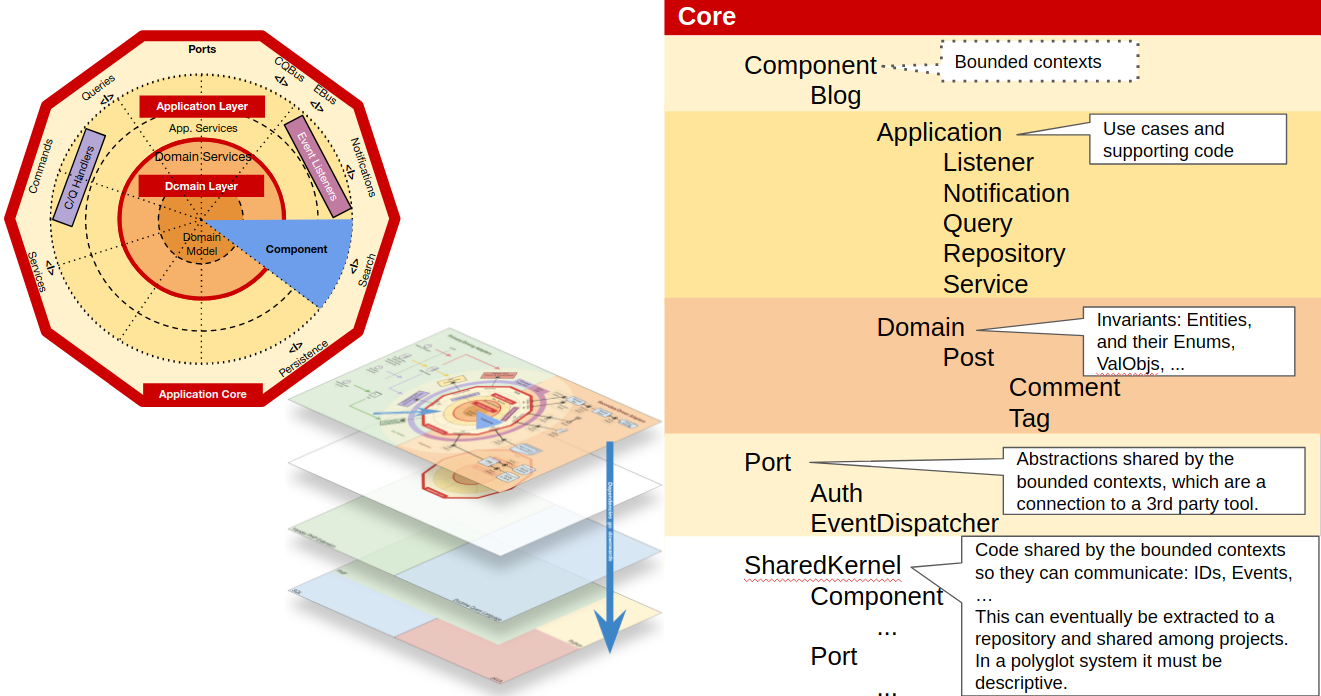
Shared Kernel
In the Shared Kernel we will place the code that is shared among Components. After experimenting with different inner structures for the Shared Kernel, I can’t decide on a structure that will fit all scenarios. I feel that for some code it makes sense to separate it per component as we did in Core\Component (ie. Entity IDs clearly belong to one component) but other cases not so much (ie. Events might be triggered and listened to by several components, so they belong to none). Maybe a mix is the better fit.
Userland language extensions
Last, but not least, we have our own extensions to the language. As explained in the previous post on this series, this is code that could be part of the language but, for some reason, it’s not. In the case of PHP we can think, for example, of a DateTime class based on the one provided by PHP but with some extra methods. Another example could be a UUID class, which although not provided by PHP, it is by nature very aseptic, domain agnostic, and therefore could be used by any project independently of the Domain.
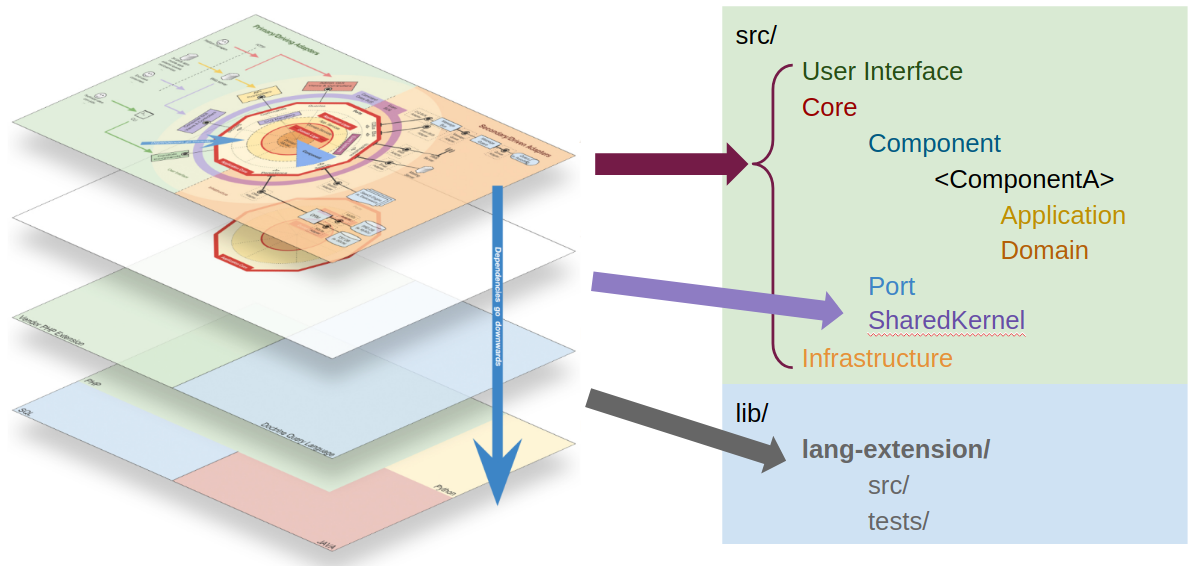
This code is used as if it would be provided by the language itself, so it needs to be fully under our control. This doesn’t mean, however, that we can’t use 3rd party libraries. We can, and should use them when it makes sense, but they must be wrapped by our own implementation (so that we can easily switch the underlying 3rd party library) which is the code that will be used directly on the application codebase. Eventually, it can be a project on its own, in its own CVS repository, and used in several projects.
Enforcing the architecture
All these ideas and the way we decide to put them to practise, are a lot to take in, and they are not easy to master. Even if we do master all this, in the end we are only humans, so we will make mistakes and our colleagues will make mistakes, it’s just the way it goes.
Just like we make mistakes in code and have a test suite to prevent those mistakes from reaching production, we must do the same with the codebase structure.
To do this, in the PHP world we have a little tool called Deptrac (but I bet similar tools exist for other languages as well), created by Sensiolabs. We configure it using a yaml file, where we define the layers we have and the allowed dependencies between them. Then we run it through the command line, which means we can easily run it in a CI, just like we run a test suite in the CI.
We can even have it create a diagram of the dependencies, which will visually show us the dependencies, including the ones breaking the configured rule set:
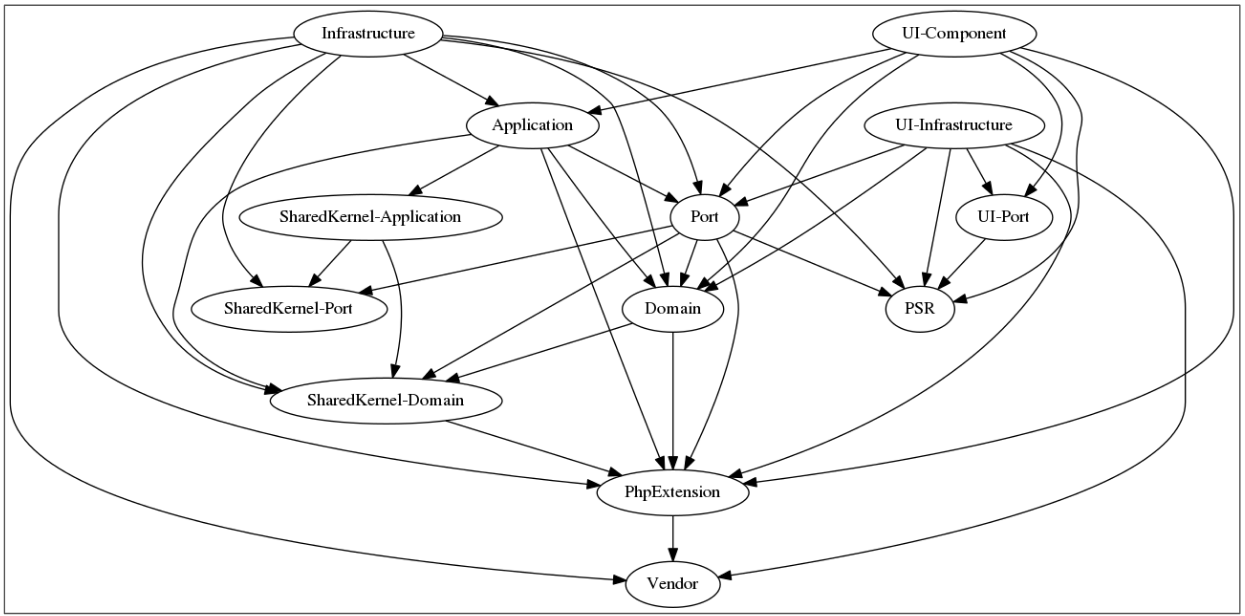
Conclusion
An application is composed of a domain and a technical structure, the architecture. Those are the real differentials in an application, not the used tools, libraries, or delivery mechanisms. If we want an application to be maintainable for a long time, both of these need to be explicit in the codebase, so that developers can know about it, understand it, comply to it and further evolve it as needed.
This explicitness will help us understand the boundaries as we code, which will in turn help us keep the application design modular, with high cohesion and low coupling.
Again, most of these ideas and practices I have been talking about in my previous posts, come from developers far better and more experienced than me. I have discussed them at length with plenty of my colleagues in different companies, I have experimented with them in codebases of enterprise applications, and they have been working very well for the projects I’ve been involved with.
Nevertheless, I believe there are no silver bullets, no one boot fits all, no Holy Grail.
These ideas and the structure I refer in this post should be seen as a generic template that can be used in most enterprise applications, but if necessary it should be adapted with no regrets. We always need to evaluate the context (the project, the team, the business, …) and do the best we can, but I believe and hope that this template is a good starting point or, at the very least, food for thought.
If you want to see this implemented in a demo project, I have forked and refactored the Symfony Demo application into using these ideas. You can check how I did it here.

Thank you Herberto for this outstanding series.
One question: How would you realise a UI dashboard component, which should offer the same forms from other UI components?
Following the Core layer principle it would be a SharedKernel, but a very heavy one compared to the whole code of the UI and just because of the dashboard. Or without SharedKernel by creating an exception for the dashboard to allow access to other components.
I tend to the exception but would like to hear your opinion.
LikeLike
I would put it in the SharedKernel.
Indeed with Frontend projects, a lot of code will end up in the SharedKernel, in fact the whole design system will be there. In the CoreComponents we will have mostly pages and some UI components that are too specific to a CoreComponent and not reusable, we only do those to simplify the code.
In these frontend projects, I recommend putting the whole design system in the SharedKernel, organising it following atomic design principles plus design tokens, Layouts and templates.
You can see an example with ReactJs here: https://github.com/hgraca/explicit-architecture-reactjs/tree/workshop-gist_explorer/src/UI/SharedKernel
LikeLike
Hi Herberto,
Why you placed both of repository interfaces and their implementations in the application layer? It is to make sense we put repository interface as port in this layer, why its implementation is not in the infrastructure layer? So far for all ports we defined adapters in infrastructure layers.
LikeLike
U can use the repositories as adapters, or create a port/adapter for the ORM.
If the 1st option, u put the repositories in the infrastructure, otherwise u put them in the Application layer. In this last case, the repositories interfaces are still useful cozz for testing u can use an in-memory repository, speeding up the tests significantly.
LikeLike
Thanks for your guide 🙂
LikeLike
Hi,
Is Userland language extensions layer something like a cross-cutting concerns layer or package? That all our layers could use them, and they are global to the entire system. We could maintain it in a separate repository for using all other projects like a common library?
LikeLike
Yes, I’m pretty sure I mention that in my blog post.
LikeLike
Thanks.
LikeLike
Hello Herberto! Thanks a lot for your posts! I am studying Clean (Explicit) for some time, and after your article my understanding of Clean way become cleaner)). In process of reading some questions arises and I can’t find the answers maybe you can answer some..
1. You wrote that “3rd party libraries… they must be wrapped by our own..” But how properly wrap them? Let’s assume that I need some specific library functionality (function X()) inside my interactor/usecase. Of course I can’t do a direct call, so i need to wrap the function X(), so I create an interface (at interactor/usecase level) which represents functionality I need at this interactor/usecase, so my interactor depends on interface. But I have also to wrap the library call of X(). Library is 3rd party thing and the place for it in the very outer circle (Frameworks and Drivers in UB notation where UI and etc lives). As I understand the interface is a port and wrapper is an adapter. So the adapter’s place int the InterfaceAdapters circle, 3rd from the center (UB). I can’t figure out how to call library function from adapter without violating the rule of dependencies? In my attempts I end up with call from the inner circle (Adapters) to the outer (Framworks) how to deal with this. I think i misunderstood somthing…
2. Another questions is about Repositories/Gateways.
a) Should I have one repo/gateway for every Entity? For example UserGateway, SessionGateway, ProductGateway, so i will have a lot of gateways/repositories.
b) Or should I create one gateway per DB like one for all Entities in Redis one for Entities in MySQL for example, and every Gateway will have a bunch of methods for concrete usecases ? In this case Repo/Gateway interfaces will contain a lot of methods. Which is not very flexible I assume.
c) Or maybe to create a Gateway per one Interactor/Usecase ? In this case it will be Gateway which will do request to two different DBs seems it is not a good idea.
Thank you a lot! Forgive me for stupid questions(
LikeLike
Hi, let’s see if i can help 🙂
A) The adapters are outside the application core, they are outside the most important boundary, so adapters can depend on the 3rd party library. The isolation we care most about is the core (our actual application) from external details. The 2nd mist important is the isolation of the domain layer from the application layer (use cases, etc).
B) I recommend one repository per entity and per data source, although (very) occasionally one repository for an aggregate (set of related entities) is enough. Otherwise we end up with a huge gateway class which breaks SRP.
C) I wouldn’t do that either as it breaks SRP again (1 class => several sources).
No question is stupid. Furthermore, this stuff can be quite overwhelming and confusing at first, and definitely there is no silver bullet, no one-boot-fits-all. So don’t feel bad about being confused.
Stay strong on your search for knowledge and understanding, the most important is that we do our best.
Hope I could help. 🙂
LikeLike
Thanks a lot, Herberto! You helped me so much with your answer and moral support! And your example of architecture at your github ( found it yesterday)! Will keep going! God bless you!
LikeLike
@hgarca: but doesn’t it seem like a lasagna to you?
https://bit.ly/2ZWGR8M
LikeLike
Not really, it just feels unfamiliar cozz i have no idea of what the domain is. However, i can see “shop”, “owner” and “products”, so i might guess its a shop, maybe even a webshop. If this is the case, if the whole application is about modeling a shop, then i would remove the “shop” folder and I would put the “owner” and “products” directly under “components”, because “shop” is not a component, it is the application itself. Each of those components will then have their own application and domain layers.
Hope this makes it a bit more clear.
In any case, more important than doing this, is that you find a way to create explicit modules that makes sense to your team.
Good luck 🙂
LikeLike
Hi Herberto,
first of all i would like to thank you for this great series of articles dealing with the onion-architecture and the patterns going along with it (like ports and adapters).
I totally agree with your source-code structure representing the architectural-model – makes totally sense to me.
But i have some “mental problems” how to package it in binaries using .NET Core and assemblies.
One could go the “technical approach” and create an assembly for each ring: so i have one for the domain-objects (DTOs) and domain-services, one assembly for the ports (interfaces), one assembly for the application services and so on. It is good, because by watching my references, i can ensure, that dependencies go only inward. But what i totally miss, is the bounded context (aka component) – it is not represented!
So i could use the more “functional approach” and put each bounded context (component) in its own assembly separating the rings within the assembly as project folders. So at least i also have an assembly for the shared kernel and the ports (interfaces). But in this model, i have problems, how to reuse the DTOs and domain-services, that are required in different/multiple bounded contexts? (i know, that DDD suggests to have your own domain-model for each bounded context – but you never would implement domain-services redundantly, if you have to use in two bounded contexts).
What would be your opinion or recommendation how to put your source-structure in binary packages fpr deployment (for .NET these are the assemblies).
Thanks a lot in advance!
LikeLike
Hi Reinhold, unfortunately I don’t have experience with .NET and packaging its binaries, so I’m afraid any advice i can give you is not gonna be worth much.
Nevertheless, i dare say that from the 2 options you mention, i feel the second one is the best. Also, can’t those binaries share libraries? If so, you could have a “separate” library with your shared kernel, the DTOs and so on that those binaries need to share. Maybe that would work, but I don’t have experience with it, so…
LikeLike
Hi Herberto,
tanks a lot for your answer.
Even if you don’t have experience with .NET, your assessment of the options is very valuable for me – so thanks for that!
And indeed i go with you: the second option (“functional approach”) is the one, that i prefer also.
I think, i would have two “base-assemblies” to share between the rings: the “classic” shared kernel containg the technical base-classes/interfaces and kind of “base-domain-assembly” containing the DTOs and domain-services for reuse.
So, that sounds good for me 🙂
Thanks again for taking your time and answering my question.
Keep on going with these great articles containing a lot of valuable information!
LikeLike
Hi Reinhold and Herberto,
I’m also trying to understand something more about this fantastic series of articles.
I want to let you know that I am also a .Net developer.
Indeed, this architecture is difficult to package in .Net
A package approach for each ring does not fully conform to Herberto’s model because we have the concept of component.
A package should only be a domain plus a piece of architecture, leaving the doors behind.
What do you mean @Reinhold with the phrase: “But what I totally miss, is the limited context (also known as component) – it is not represented!”?
Isn’t the limited context the sharedkernel?
And in addition it is not clear to me what with the question:
So I could use the more “functional” approach and put each limited context (component) in your assembly that separates the rings within the assembly as project folders. So at least I also have an assembly for the shared kernel and ports (interfaces).
But in this model, I have problems, how to reuse DTOs and domain services, which are required in different / multiple contexts?
Can you explain better or give a practical example on github?
I’m also trying to make a project that summarizes all the concepts like Herberto in .Net, my git address is this: https://github.com/Razzo78
Soon I want to publish a project on which I have been studying for at least 3 years.
Can you help me finish it? Thx!
LikeLike
Hi Herberto, thank you very much for your article. Could you please explain, how to structure the directories when you have optional, composer based plugins in this architecture? E.g. you have a composer package as plugin for your software, which includes
a) a complete new domain component with UI-extensions, domain logic etc..,
b) a little plugin which only has a new notification client (or persistence adapter or so). Would you prefer to add the
infrastructure folder in the plugin?
LikeLike
I think the external modules should not dictate what tools you use in your main application.
So, those composer packages should be configured in your main application, using Dependency Injection, to use whatever tools you are using.
What those packages might need to provide are the ports, to which your main application will need to have an adapter to provide the package with.
Hope this helps.
LikeLike
Hi Herberto,
First of all thanks for your blog series which are certainly insightful. We’ve had quite some debate on how to interpret certain aspects of the architecture so maybe you could clarify a few things for us.
1) Within the diagram, message bus and the two interfaces accompanying it are explicitly drawn on the right-hand side of the diagram which implies “secondary / driven adapters”. But when implementing an event-based architecture you would say that an event is a driver to which your application needs to react, right?
2) A similar debate we had concerning the event listeners / C/Q handlers as drawn in the diagram. On one hand we would expect the application-layer circle to have / use both adapters types, but then what use is there to split them up like this. Especially when you have adapters which do both like a service bus would.
3) The concept / scope of a “component” is also a bit vague to us. The diagram shows a component that I would label “search”, which is on the infrastructure side of things (makes sense). So a component which also has UI (left-hand side I assume) would need to interact with the search component using messages as defined in the kernel? How does this translate into a solution / project / library design? As in: what would be the normal scope of “a component” and would that not always require quite a bit of communication with other components? We can decouple that of course, but changes would still impact a multitude of components in that case, or require some sort of (usually complex) backwards compatibility scheme.
For my personal understanding it would help a lot to have some sort of hello-world / sample style application that shows some of the concepts. Once I have the feeling I really grasp this well I might create one for .NET Core programming.
LikeLike
Hi,
Well, the first thing you need to keep in mind is that what I say in my blog posts, as well as what other ppl more experienced than me say in their blog posts, none of it is a holy grail. There are many ways to look at it, and it doesn’t mean that any of them are wrong, maybe not even better or worse. What is really important is that the team is united around that vision for the system. Mistakes will be made, solutions will be found, improvements will be implemented, and the system and the team grow together.
Now to the point:
1) What I draw on the right side is the tool that makes it possible to send and receive events. Not the events nor the listeners themselves.
The events, you can regard them as a trigger to a use case, just like an HTTP request is a trigger to a use case. In this case, the event listener can be seen as an adapter that extracts data from that event and passes it on to a use case. This means the events and listeners would be in the UI layer.
But you can also see the events as a slightly different form of commands, and the listeners as a slightly different type of command handlers. The listener might even have the use case logic in it, as opposed to just triggering logic that is somewhere else. In this case, the events and listeners are part of the application layer.
As I mentioned above, there are different ways to look at it, none of it is wrong by default, it depends on what your team is more comfortable with. 🙂
2) The application circle does not have adapters, the adapters are on the UI layer and adapt a delivery mechanism to a use case. The application layer contains the use cases. That said, you can most definitely have some kind of “handler” that is triggered by both commands and events. The reason to slipt them up is not technical, is conceptual: separation of concerns. I like to be able to look at a class name and know exactly what type of code it has inside, where it should be placed, how it should be used, and when it is triggered:
– if it’s a command handler, it is triggered directly by a user action, it has only one command that can trigger it, and that command lives next to the handler;
– if it’s an event listener, it is triggered as a result of a use case, after a command handler has been executed. It can be triggered by an event dispatched from several locations/use cases. There might be several listeners being triggered by the same event, so it doesn’t make sense for a listener to be located next to the event it listens to.
The danger of having a “handler” that handles both commands and events, is that at some point we end up losing track of that triggers what and when.
3) The application core (or kernel as you call it), is the only thing containing components. Components are modules specific to the domain. An adapter and other libraries are also modules, but they are not related to the domain, they could be used in any project.
This means that in the application core we only have code that relates to the domain.
Text search is not part of the domain, so the application core should know nothing about it.
If your UI needs to expose text search directly, then the controller (or whatever you use) should use the text search port/adapter directly, we don’t need a component for that. Since the port belongs to the application core and the UI depends on the application core, this is still correct from the conceptual/dependencies point of view.
You can see an example in PHP here: https://github.com/hgraca/explicit-architecture-php
Hope this helps you and doesn’t confuse you even further. 😀
LikeLike
Thanks! It definitely helps and thanks for replying this quickly. I completely understand your point about this not being a holy grail, we’re not treating it like this. But architectural concepts need to be clear and understandable if multiple development teams need to align on it. There was quite a bit of debate about some concepts of this model so by definition that brings along issues in alignment over teams when people have different views on what an architecture model should mean / translate into. Your explanation has clarified some things but I do believe we need to do some additional work on making a clear cut picture that all devs can understand without too much hassle. Oh and thanks for the sample link, I’ll take a look (but my PHP is a bit rusty to say the least).
LikeLike
Cool, glad i could help a bit, and if you have more questions, just ask ahead, i love thinking about this stuff and I’ll do my best to give a miningful answer. 🙂
LikeLike
Hi Herberto!
Thank you very much for the article!
There is a tool which can be used to keep architecture from inadvertent changes: https://github.com/BenMorris/NetArchTest
It’s new but it can implement some of the checks.
LikeLike
Hey, thank you very much. I was looking for dotnet options.
LikeLike
Thank you for taking the time to put these chronicles together. Very well presented and an excellent compendium of best of breed software architecture practices, based on well founded research material.
LikeLike
Hello, I just wanted to thank you for the Chronicles. It is a fantastic compilation of best of the best all put together in very clear and easy to grasp way. As I read through I realized we invented many of the principles for ourselves, but reading the materials was the spark I needed for some time to bring our architecture up a level and helped me realize what our problems are. Very well done! Thank you!
LikeLike
Hi Herberto! I’ve been waiting a long time for this post, and am not disappointed, so thank you!
I do have two questions:
1. An organisational question: In your Core\Port namespace to separate between driven adapters and driving adapter in any way, or do you just put them all there and they have one use or the other.
2. I agree with an assertion you made in a prior post where within the blue slice of a component, this is where the CQRS separation would be, if you were using it. The closest thing I see there is the Component\Blog\Application\Query namespace. Is that what is intended here? Or is this something different?
I’m very curious about item 2 here because I expect my Query side to be full of other DTOs covering all of the query operations on the various components and for that reason would envision them in a location like Component\Blog\Query\Post. This way the Query side is completely disjoint from Domain. Admittedly, with many components this would make things further apart than I might like. Perhaps somewhere like Components\Blog\Domain\Query to keep them close?
So, I guess question 2 is: Because the Query side may vary so much from the read side in complexity and models, where do you slot it in?
LikeLike
Hi, tkx.
I separate them. The driven ports live in
Core\Port, while the driver adapters are, for example, the controllers which live inUserInterface\...and connect to the driver ports which are the use cases living inCore\Components\SomeComponent\Aplication\.... The driven adapters live inInfrastructure\<Tool>\<Vendor>\....LikeLike
That makes sense; no real need for a separate namespace since the client (UI) must conform to what’s provided.
Any thoughts on my second question? Where you slot in the query side if a component is following CQRS?
LikeLike
With CQRS, the command hand handler are the use case, so they go together in the application layer.
I never needed to use a query bus, i simply use query objects. For those, it depends on where they are used.
If they are specific to a controller&template, i place the query object there, next to the controller and template.
If they are reusable, i place them in the Application layer.
LikeLiked by 1 person
I would like to expand your questions with another one:
3.) If you have two components and they both have e.g. an account concept and they also both define a repository interface AccountRepository as a driven port. This will lead to a name clash in the (shared) ports namespace. How do we handle this? I wouldn’t like to operate with prefixes or suffixes to qualify the relation of the repository to its origin (the component).
LikeLike
Abstract the persistence mechanism from the core is the most difficult port/adapter case I have found, and we can do it in 2 different ways.
The way you are doing it is using the repositories as adapters. This is the easiest, but not the most correct as it leads to the issue you mention, and also to the fact that being a port, any component can use that repository and access directly to data that doesn’t belong to it.
The most correct way, however, is wrapping the persistence lib in an adapter, which reflects a persistence port. This port is then used in repositories, which belong in specific components. Since each repository is in its own component, they don’t have name clashes.
As I mention in my article, the repositories belong in the application layer, they are a specific type of services, they are not adapters.
LikeLike
Hi Herberto,
Thank you again for the blog. It has helped me a lot, one question.
Let say I want to implement Infrastructure\Persistence\ORMAdapter in UserRepository(PersistenceInterface $persistence), when I do this in Symfony I have to use
$this->entityManager->getRepository(User:class); inside the UserRespository so I can have access to the type of repository that I need in this case is the User, but what if I pass this same ORMAdapter to the PaymentRepository(PersistenceInterface $persistence) I can still have access the User object by using ORMAdaper? by doing this, any component will have access to data that should not have access to.
The other option is to create instead a Infrastructure\Persistence\ORMUserAdapter with his specific Interface ORMUserInterface for example.
What do you think?
LikeLike
I think using $this->entityManager… inside the repository is using a service locator pattern, which should only be used in very restricted scenarios, usually related to building objects.
So, if instead of that, u use dependency injection, u can inject the query builder and build your query. You don’t need the special repository provided by Symfony.
LikeLike
Thank you for responding.
It makes sense to use a query builder because I can switch to another db like SQL and still be able to query by using the same quieryBuilder, but the issue still remains by having access to all the tables in a monolith database, does not this violates the container principle of restricting the access to other containers?
LikeLike
It depends. Writing data should only be allowed from the component that owns that data, reading not really, as long as we use raw queries without instantiating entities from another component.
With the query builder, you can do both.
To enforce these architecture rules, we can use static analysis: query objects can reach any table, repositories (which instantiate entities, which r used for writing) can only query a subset of tables.
LikeLike
Thank you Herberto, I really appreciate your time given, I will search for static analysis.
best,
LikeLike